안녕하세요. 리디 백엔드 엔지니어 강규입니다.
오늘은 Event Driven Architecture에서 메시지 발행의 신뢰성을 보장하는 Transactional Outbox 패턴을 소개하고, 이를 리디 서비스에 적용하며 느낀 바를 공유하고자 합니다.
Transactional Outbox 패턴이란 무엇인가요?
Event Driven Architecture를 따르는 서비스에서는 대개 Message Broker를 이용해 다양한 메시지(이벤트)를 publish(발행) 하고, 그에 연관된 작업을 비동기적으로 처리하여 시스템을 통합합니다.
이때 DB 트랜잭션을 실행한 뒤 연관 메시지를 Message Broker에 publish 하게 되는데, 때로 메시지 publish가 반드시 완료되어야 하는 경우가 있습니다.
리디 주문 기능을 예로 들어볼까요? 먼저 주문이 발생하면, 사용한 캐시·포인트 금액을 차감하고 상품을 지급하며 주문 완료로 상태를 바꾸는 DB 트랜잭션이 발생합니다. 그리고 Message Broker에 주문 완료 메시지를 publish 합니다.
DB 트랜잭션은 DB 차원에서 원자성(atomicity)을 보장하므로 트랜잭션에 포함된 query들은 원자적으로 실행되지만, 대개는 DB와 Message Broker가 다른 기종이라 원자적인 처리가 불가능합니다.
따라서 DB 상 주문 완료 처리가 되었더라도 Message Broker에 메시지를 publish 하는 데 실패할 수 있고, DB의 주문 완료 처리를 rollback 하기도 어렵습니다.
이런 문제를 해결하기 위해 Transactional Outbox 패턴이 등장합니다. Outbox는 주로 웹 메일에서 ‘보낸 편지함’을 의미합니다. Outbox를 Message Broker에 publish 할 메시지로 대응해서 생각해 보면 패턴의 이름을 이해하는 데 도움이 됩니다.
즉, Transactional Outbox 패턴은 Message Broker로 publish 하려는 메시지의 생성을 DB 트랜잭션에 포함시켜서 원자적으로 처리되게 하는 것을 의미합니다.
리디에 Transactional Outbox 패턴을 도입한 배경
지난번 ‘리디에서 Kafka를 사용하는 법‘에서 소개한 것처럼, 리디 서비스는 Kafka를 중심으로 통합되고 있습니다. 그리고 API, batch process, Kafka consumer 등 다양한 서비스들이 데이터 영속화를 위해 MySQL를 사용합니다. 주로 MySQL을 이용해 비즈니스 로직을 처리하고, 비동기적인 처리를 위해 메시지를 Kafka에 publish 합니다.
Kafka 도입 초기에는 아래 코드와 같이 메시지를 publish 했습니다. DB 트랜잭션이 완료된 이후 Kafka에 메시지를 publish 하고, 실패한 메시지를 dead_letter_queue DB 테이블에 저장한 뒤 별도의 batch process에서 retry를 하는 방식이었죠.
CREATE TABLE `dead_letter_queue` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`topic` varchar COLLATE utf8mb4_unicode_ci NOT NULL,
`key` varchar COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`message` mediumblob NOT NULL,
`status` enum('queued','processed','skipped') COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT 'queued',
`updated_at` datetime NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp(),
`created_at` datetime NOT NULL DEFAULT current_timestamp(),
PRIMARY KEY (`id`),
KEY `idx_status` (`status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;const publishToKafka = async (record: ProducerRecord, options: ProducerSendOptions) => {
try {
return await producer.send(record);
} catch (err) {
...
if (options.useDeadLetterFallback) {
await queries.insertDeadLetterQueue(record);
}
}
};
await db.transaction(async (trx) => {
...
await queries.insertOrder(order).transacting(trx);
});
await publishToKafka(record);그러나 코드 베이스에서 Kafka를 점점 더 많이 도입하게 되자, 아래와 같은 한계가 드러났습니다.
- DB 트랜잭션과 메시지 publish를 원자적으로 처리할 수 없기 때문에, DB 트랜잭션이 완료되어도 메시지 publish를 보장할 수 없습니다.
- 일정 시간 간격으로 batch process가 실행되면서 retry가 되다 보니 신속하지 않았습니다.
- 메시지 간 publish 순서가 중요한 경우, 토픽의 경우 retry 되는 메시지가 늦게 publish 되면서 기대했던 순서가 뒤바뀔 수 있습니다.
이러한 문제를 해소하기 위해 앞서 설명한 Transactional Outbox 패턴의 도입을 검토하게 되었습니다.
어떻게 Transactional Outbox 패턴을 구현했나요?
Transactional Outbox 패턴을 구현하는 방식은 대표적으로 Polling Publisher 와 Transaction Log Tailing 이 있습니다. 두 방식의 가장 큰 차이점은 publish 할 메시지를 구성하는 데 있습니다.
Polling Publisher 방식으로는 Outbox DB 테이블에 polling 하는 것만으로 publish 할 메시지를 가져올 수 있습니다. DB 트랜잭션이 실행되는 시점부터 publish 할 메시지 정보를 각 비즈니스 로직에서 생성하여 Outbox DB 테이블에 저장하기 때문입니다.
Transaction Log Tailing 방식은 publish 할 메시지를 on-demand로 생성합니다. DBMS마다 트랜잭션이 처리되면 log(예를 들어 MySQL의 경우 binlog)를 생성하게 되는데, 해당 log에 대한 CDC(Change Data Capture)를 구현하는 것이죠.
먼저 Polling Publisher 방식은 전반적인 구조가 단순해서 구현하기 간편하지만, 비교적 높은 비용의 polling이 DB 부하로 이어질지도 모른다는 우려가 있었습니다.
반면 Transaction Log Tailing 방식은 polling 방식의 단점이 없는 대신, MySQL binlog에 대해 CDC를 구현하고 그 결과를 바탕으로 Kafka consumer에서 사용하는 메시지 포맷으로 데이터를 생성하는 작업이 필요합니다. 주로 직접 binlog에 접근하는 방식보다 Debezium과 같은 도구를 통하는 것이 권장되지만, CDC 도구를 학습하고 운영하는 것과 CDC 도구에서 생성하는 메시지의 schema 를 관리하는 데 적지 않은 비용이 들 것 같았습니다.
우선 Polling Publisher 방식을 사용해 Message Relay를 구현하기로 하고, polling으로 인한 영향은 모니터링해 보면서 판단하기로 했습니다. 이제부터는 실제 구현 과정의 이야기를 들려드리겠습니다.
Outbox DB 테이블 Schema 정의
CREATE TABLE `message` (
`id` bigint NOT NULL AUTO_INCREMENT,
`topic` varchar NOT NULL,
`type` varchar NOT NULL,
`key` varchar DEFAULT NULL,
`payload` longtext NOT NULL,
`source` varchar NOT NULL,
`created_at` datetime NOT NULL DEFAULT current_timestamp(),
`updated_at` datetime NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp(),
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
CREATE TABLE `processed_message` (
`id` bigint NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;message 테이블에는 Message Broker로 publish 할 메시지 정보를 저장하고, processed_message 테이블에는 publish 되거나 publish가 불가능해서 skip 하려는 message id를 저장합니다.
초기 구현에는 processed_message 테이블 없이 message 테이블만을 사용해서 처리 완료된 row를 바로 상태 업데이트하거나 삭제했는데, 복수의 Message Relay node를 운영하는 상황에서 종종 DB Lock 관련 문제가 발생했습니다. 이 문제를 개선하고자 현재는 processed_message 테이블을 추가해서 처리 완료된 row를 임시로 저장해두었다가 삭제하는 방식을 사용하고 있습니다. 이는 후반부에서 자세히 소개하겠습니다.
Outbox Polling과 Kafka Publish
interface Message {
id: number;
topic: string;
type: string;
key: string | null;
payload: string;
source: string;
created_at: string;
}
const publishMessages = async (messages: Message[]) => {
const topicToMessages = groupBy(messages, (m) => m.topic);
try {
const sendBatchResult = await producer.sendBatch({
topicMessages: Object.entries(topicToMessages).map(([topic, msgs]) => ({
topic,
messages: msgs.map((msg) => {
const event = new CloudEvent({
data: JSON.parse(msg.payload),
...
});
return {
headers: {
'content-type': 'application/cloudevents+json; charset=UTF-8',
},
value: event.toString(),
};
}),
})),
});
...
// succcessMessageIds: Kafka publish가 성공한 message.id
// failMessageIds: Kafka publish가 실패한 message.id(재시도 가능)
return { successMessageIds, failMessageIds };
} catch (e) {
...
// skipMessageIds: Kafka publish가 불가능한 message.id(잘못된 json format 혹은 Kafka topic 미생성 토픽)
return { successMessageIds: [], skipMessageIds: ... };
}
};
const relayMessages = async () => {
const lock = await redlock.lock(redisLock.key, redisLock.ttlInMs);
if (!lock) {
return { messages: [] };
}
try {
return await db.transaction(async (trx) => {
...
// findMessagesToPublish():
// SELECT `message`.* FROM `outbox`.`message`
// LEFT JOIN `outbox`.`processed_message` ON `processed_message`.`id` = `messsage`.`id`
// WHERE `processed_message`.`id` IS NULL
// ORDER BY `message`.`id` ASC
// LIMIT ${BATCH_SIZE}
const messages = await queries.findMessagesToPublish(BATCH_SIZE).transacting(trx);
if (!messages.length) {
return { messages: [] };
}
const { successMessageIds, skipMessageIds } = await publishMessages(messages);
const processedMessageIds = [...successMessageIds, ...(skipMessageIds ?? [])];
if (processedMessageIds.length) {
await queries
.insertProcessedMessages(processedMessageIds)
.transacting(trx);
}
return { messages, processedMessageIds };
});
} finally {
await lock.unlock();
}
};서로 다른 물리 instance에 각각 하나씩 최소 2개의 node를 배치하여, 만일 장애가 발생해 하나의 node가 shutdown 될 경우에도 다른 하나의 node가 동작할 수 있도록 했습니다.
복수의 node로 운영한다면 서로 다른 node에서 메시지가 중복으로 처리될 수 있기 때문에 Redis lock과 MySQL record lock를 함께 사용해서 이를 해결했습니다. Redis lock을 획득한 node에서 MySQL record lock 획득을 시도할 수 있게 해서, MySQL record lock wait에서 발생하는 DB 부하를 낮게 유지하면서 메시지가 중복으로 처리되지 않도록 했습니다.
publish 할 메시지를 가져올 때, processed_message 테이블에 없는 메시지만 가져와야 하기 때문에 message 테이블과 processed_message 테이블 사이에 LEFT JOIN이 필요합니다. processed_message 테이블에 있는 row가 적을 수록 SELECT 쿼리 성능이 좋아서 processed_message 테이블의 row 개수는 일정한 수준을 유지합니다.
처리된 메시지의 삭제
처리된 메시지를 삭제하는 구현의 초기 방식은 아래와 같았습니다.
1. published_ids := message publish
2. DELETE FROM message WHERE id in (:published_ids)DELETE query가 실행되는 시점에 INSERT INTO message VALUES (?) query가 빈번하게 호출되는데, INSERT INTO message VALUES (?) query에서 획득하는 message.id에 대한 lock 때문에 DELETE FROM message WHERE id in (?) query의 lock wait가 길어지는 경우가 종종 발생했습니다.
message.id에 대한 lock 경합을 줄이는 것이 필요해서, publish 완료된 메시지를 바로 삭제하지 않고 processed_message 테이블에 저장해두었다가 나중에 삭제하도록 수정했습니다.
1. published_ids := message publish
2. INSERT INTO processed_message VALUES (:published_ids)그리고 INSERT query에서 접근하는 message.id 값의 대역과 DELETE query에서 접근하는 message.id 값의 대역이 겹치지 않도록 최소 간격을 벌려, 현재 기준에서 조금 오래된 row만을 삭제해서 lock wait가 길어지는 경우를 줄였습니다.
예를 들어 MAX_ID_MARGIN_TO_DELETE 값이 1,000이라고 하면, 가장 최근 publish 된 message.id로부터 1,000 작은 id까지를 삭제합니다.
const deleteProcessedMessages = async (processedMessageIds: number[]) => {
const maxMessageIdToDelete = Math.max(...processedMessageIds) - MAX_ID_MARGIN_TO_DELETE;
// findMessageIdsToDelete():
// SELECT `id` FROM `outbox`.`message` WHERE `id` < ${MAX_ID_MARGIN_TO_DELETE}
// LIMIT ${DELETE_BATCH_SIZE}
const messageIdsToDelete = await queries.findMessageIdsToDelete(
maxMessageIdToDelete,
config.deleteBatchSize,
);
if (!messageIdsToDelete.length) {
return;
}
await db.transaction(async (trx) => {
await queries.deleteProcessedMessages(messageIdsToDelete).transacting(trx);
await queries.deleteMessages(messageIdsToDelete).transacting(trx);
});
};위와 같이 개선했을 때 processed_message 테이블에 일정한 개수의 row가 유지되고, findMessagesToPublish() SELECT query에서 LEFT JOIN을 하게 되면서 SELECT query 성능을 조금 희생했지만 삭제 latency가 상당히 개선되었습니다.
Message Relay의 전체적인 동작 및 모니터링
지금까지 추가한 함수를 조합하여 Message Relay loop를 구현합니다.
배포 등의 원인으로 process가 종료될 수 있는데, loop 처리 중에 process가 종료되는 것을 막기 위해 현재 실행되는 loop가 종료될 때까지 delay 하고 있습니다.
let shouldTerminate = false;
let jobOngoing = false;
const terminate = async () => {
shouldTerminate = true;
while (jobOngoing) {
pino.warn('Delay 1s until current job will be processed...');
await delay(1000);
}
...
process.exit(1);
}
['SIGTERM', 'SIGINT'].forEach((signal) => {
process.on(signal, () => terminate());
});
while (!shouldTerminate) {
jobOngoing = true;
try {
const { messages, shouldDelay, processedMessageIds } = await relayMessages();
if (processedMessageIds?.length) {
deleteProcessedMessages(processedMessageIds);
}
const messageElapsed = messages.length
? Math.abs(new Date().getTime() - new Date(messages[0].created_at).getTime())
: 0;
if (messageElapsed >= 60 * 1000) {
logError(new Error('message-relay processing elapsed.'));
}
} catch (err) {
logError(err);
}
jobOngoing = false;
}위 코드 블록에서는 생략했지만 Datadog을 통한 지표 모니터링을 위해 top level while문의 loop 하나가 Datadog의 span으로 기록하도록 처리되어 있습니다.
아래와 같이 Datadog을 이용해서 처리량, 에러 빈도, latency 변화를 모니터링하고 DB query 지표 모니터링도 진행하고 있습니다.
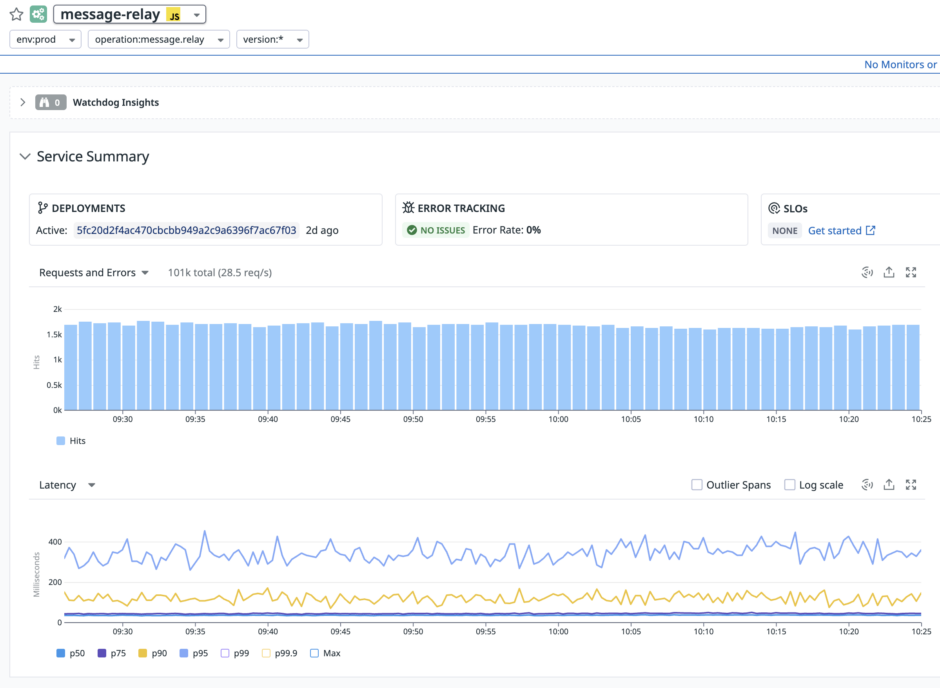
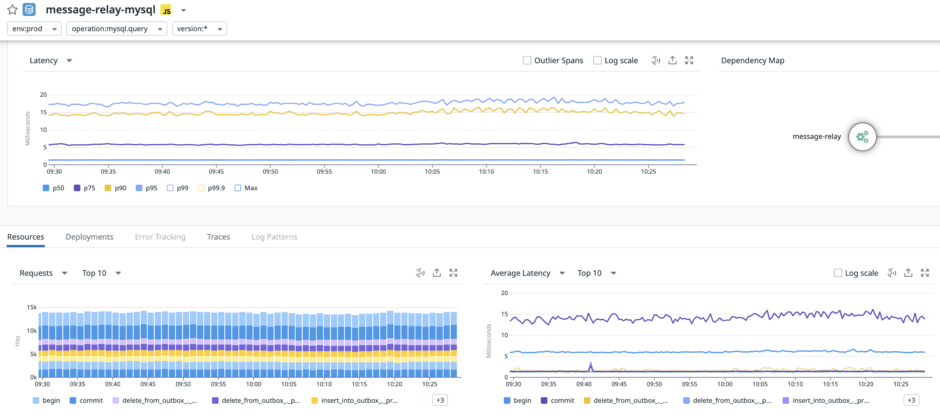
현재 시각과 메시지 입력 시각이 일정 수준 차이 나면 Message Relay의 처리가 지연되고 있는 것으로 판단해서 에러 트래킹 서비스에 전파합니다. 또, Datadog의 monitor 기능을 통해 시간 차이와 processed_message 테이블에 유지되는 row 개수를 지속적으로 모니터링합니다. 그리고 각 monitor에 설정한 임계치를 넘으면 Slack 메신저로 alert이 발생하도록 설정되어 있습니다.


마치며
지금까지 Transactional Outbox 패턴을 리디 서비스에 적용한 경험을 전해드렸습니다.
이번에 전부 소개하지는 못했지만, Message Relay를 배포한 뒤 DB query에서 발생하는 deadlock과 lock wait를 해소하고 latency를 개선하는 등 성능 튜닝 작업을 여러 번 했습니다.
Polling Publisher 방식은 전반적으로 구현하기 간편하다는 장점이 있지만, 리디 서비스에서 공통으로 사용할 기능이기에 안정적으로 서비스를 운영하는 데는 지속적으로 모니터링하고 성능을 개선하는 노력이 많이 필요했습니다.
앞으로도 지속적으로 서비스를 보완하여 리디 고객들로부터 발생한 소중한 메시지를 Message Broker에 안전하고 신속하게 publish 하도록 노력하겠습니다.
감사합니다.
고객과 발맞춰 새로운 콘텐츠 경험을 선보이는
리디와 함께할 당신을 기다립니다.