안녕하세요. 리디 서비스백엔드팀 강규입니다.
지난 글에서 Transactional Outbox 패턴을 사용해 메시지 발행을 보장하는 message-relay를 리디에서 어떻게 운영하고 있는지 소개했습니다.
오늘은 message-relay를 운영하면서 겪은 다음 이슈를 개선한 내용을 소개하겠습니다.
- 많은 양의 메시지가 message 테이블에 입력되는 상황에서 처리된 메시지의 삭제가 지연되었을 때 select 쿼리의 latency가 저하되는 문제
- message 테이블에 대한 select for update 쿼리와 delete 쿼리의 latency가 간헐적으로 치솟는 문제
불필요한 JOIN 제거하기
기존에 message-relay는 처리할 메시지가 기록된 message 테이블로부터 메시지를 읽어서 kafka에 발행하고 processed_message 테이블에 처리된 메시지 id를 기록하는 방식으로 동작했습니다. 이러한 구조에서는 message-relay가 처리할 메시지를 가져올 때, 아래의 쿼리가 사용됩니다.
select * from message
left join processed_message on processed_message.id = message.id
where processed_message.id is null
order by message.id asc
limit 500;explain analyze를 이용해서 쿼리 실행 계획을 확인해 봤습니다.
-> Limit: 500 row(s) (cost=74826 rows=500) (actual time=72.9..73.9 rows=500 loops=1)
-> Filter: (processed_message.id is null) (cost=74826 rows=500) (actual time=72.9..73.9 rows=500 loops=1)
-> Nested loop antijoin (cost=74826 rows=500) (actual time=72.9..73.8 rows=500 loops=1)
-> Index scan on message using PRIMARY (cost=0.928 rows=500) (actual time=0.0188..28 rows=100499 loops=1)
-> Filter: (processed_message.id = message.id) (cost=0.25 rows=1) (actual time=399e-6..399e-6 rows=0.995 loops=100499)
-> Single-row covering index lookup on processed_message using PRIMARY (id=message.id) (cost=0.25 rows=1) (actual time=323e-6..323e-6 rows=0.995 loops=100499)nested loop anti join 방식으로 조회하면서, driving 테이블은 message, driven 테이블은 processed_message 테이블로 결정된 것을 알 수 있습니다. message 테이블 row를 하나씩 읽어가면서 processed_message.id = message.id 조건으로 processed_message 테이블 row를 찾고 processed_message.id IS NULL 조건에 해당하는지 확인합니다.
anti join이기 때문에 해당 조건을 만족하지 않는 row가 많을수록 실행 시간이 늘어날 것을 짐작할 수 있습니다. processed_message 테이블에 있는 처리된 메시지 삭제가 비동기로 동작했기 때문에 처리된 메시지의 삭제 속도가 메시지가 새로 쌓이는 속도보다 느려질 수 있었습니다.
즉, 많은 양의 메시지가 processed_message 테이블에 쌓여서 processed_message.id = message.id AND processed_message.id IS NOT NULL 조건을 만족하는 row가 늘어나면 위 select 쿼리의 성능이 악화될 수 있었습니다.
nested loop join으로 인해 성능 저하될 수 있는 것을 개선하기 위해서 left join을 제거하고 message 테이블 하나만 사용하도록 수정이 필요했고, 아래의 방법을 검토했습니다.
- 처리된 메시지가 다시 처리되지 않도록
message테이블에statuscolumn을 추가해서 메시지의 처리 상태를 변경해 두고 비동기적으로 삭제하는 방법 - 처리가 완료된 메시지를 동기적으로 곧바로 삭제하는 방법
처리가 완료된 메시지를 유지할 필요가 없기도 하고, 곧바로 삭제해도 delete 쿼리의 lock wait 문제가 발생하지 않도록 개선할 수 있게 되어 후자를 선택했습니다. delete 쿼리의 lock wait 개선과 관련된 내용은 이번 글에서 소개됩니다.
결과적으로 message 테이블 하나만 사용하게 되면서 테이블 row의 개수에 영향을 받지 않고 일관된 select 쿼리 성능을 유지할 수 있었습니다. 또한 처리된 메시지의 삭제를 동기로 실행하게 되면서 전반적인 코드도 간결해졌습니다.
MySQL NOWAIT
가용성을 위해 message-relay node를 2대 운영하고 있기 때문에 message 테이블 row에 적절하게 lock을 설정해서 동일한 메시지에 대해서 중복으로 처리되지 않도록 하는 것이 중요합니다. 기존에는 MySQL record lock 용도로 분리된 테이블(이하 lock 테이블)에 exclusive lock을 설정해서 동시성을 제어했습니다. lock 테이블에 exclusive lock이 성공한 message-relay node에서만 메시지를 처리할 수 있습니다. (message 테이블 row에 대한 lock 경합이 있는 상태에서 message 테이블에 직접 lock을 제어하는 것보다 lock 테이블을 분리하는 것이 message 테이블의 deadlock 문제를 회피하는 데 편리했습니다.)
두 node에서 동일한 index record에 exclusive lock을 시도하게 되면 어느 한쪽은 lock wait가 발생하게 되고, 이는 DB 서버에 대해 부하를 유발합니다. 그래서 lock을 시도하는 MySQL transaction을 Redis pessimistic lock으로 감싸서 최대한 lock wait가 발생하지 않도록 했습니다.
lock 테이블이 분리된 점과 Redis에 추가로 의존성이 발생하는 구조를 개선하기 위해 MySQL 8.0부터 사용 가능한 NOWAIT를 활용해보기로 합니다. 아래 예시처럼 NOWAIT는 lock을 설정하려는 index record가 이미 다른 transaction에서 lock을 소유하고 있다면, 곧바로 에러와 함께 쿼리가 종료됩니다.
const queries = {
findMessages: (ids: number[]) => `SELECT * FROM message WHERE id in ${ids}`,
};
await db.transaction(async (trx) => {
const messages = await queries
.findMesssages(messageIds)
.forUpdate()
.noWait()
.transacting(trx);
...
}).catch((e) => {
// NOWAIT가 사용되었을 때, 다른 transaction에서 해당 index record에 lock을 소유하고 있다면 e.code = 'ER_LOCK_NOWAIT'로 error throw
});
}두 message-relay node의 transaction 사이에서 lock wait가 발생하지 않기 때문에 deadlock이 발생하지 않게 되는 효과를 얻었습니다. 더 이상 lock 테이블을 사용하지 않고도 message 테이블만 가지고 lock을 제어할 수 있었습니다. 그리고 lock wait로 인한 DB 서버 부하가 발생하지 않기 때문에 MySQL transaction을 감싸고 있던 Redis pessimistic lock을 제거했습니다. MySQL 테이블 하나로 lock을 제어할 수 있어 관리가 매우 편해졌습니다.
Full Scan은 한 끗 차이
아래 쿼리는 모두 message 테이블로부터 처리할 메시지를 가져오는 쿼리입니다. 두 개의 방식은 어떤 차이가 있을까요?
select * from message order by id asc limit 500 for update;ids := select id from message order by id asc limit 500;
select * from message where id in (:ids) order by id asc for update;전자는 id에 대해 오름차순으로 최대 500개의 message 테이블 row를 읽어가면서 lock을 설정하는 쿼리입니다. 후자는 id에 대해 오름차순으로 최대 500개의 message 테이블 row를 읽은 후 해당 row들의 id를 가져와서, 해당 id들에 대해서 오름차순으로 읽어가면서 lock을 설정하는 쿼리입니다.
두 방식은 반환하는 결과가 동일하기 때문에 하나의 쿼리로 보다 간단한 처리가 가능한 전자를 선택할 수 있을 것 같습니다. 하지만 두 방식은 lock과 관련하여 서로 동작이 다를 수 있어서 주의가 필요합니다.
message 테이블에 500개보다 row가 많이 있는 상황에서는 두 방식이 보통 똑같이 작동합니다. 반면 message 테이블에 500개보다 row가 적게 있는 상황에서는 다르게 동작할 수 있기 때문에 이 상황을 가정해 보겠습니다. 또한 transaction 격리 수준은 REPEATABLE READ 또는 READ COMMITTED를 전제합니다.
전자의 방식부터 살펴보겠습니다.

T1의 select for update 쿼리에서 lock을 설정하려고 할 때 T2, T3, T4의 insert 쿼리가 lock을 소유한 record를 포함해서 lock을 wait 하게 됩니다. 따라서 T2, T3, T4가 모두 commit 될 때까지 lock wait가 지속되고, T2, T3, T4가 모두 commit 된 이후가 되어야 T1의 commit이 가능합니다. 심지어 T4의 insert 쿼리는 T1보다 늦게 실행되었지만, T1의 lock wait 대상이 되기도 합니다. 이는 T1의 select for update 쿼리가 T2와 T3의 commit을 기다리고, T3이 commit 된 시점부터 T1은 T4가 commit 되는 것을 기다리기 때문입니다.
T2, T3, T4가 처리 시간이 짧게 걸리는 transaction이라면 T1에 영향이 적을 수 있겠지만, T2, T3, T4의 종료가 늦어지거나 동시에 실행되는 transaction이 더 많다면 T1의 lock wait 시간이 증가해 처리 지연이 발생하는 원인이 될 수 있습니다.
이번에는 후자의 방식을 살펴보겠습니다.
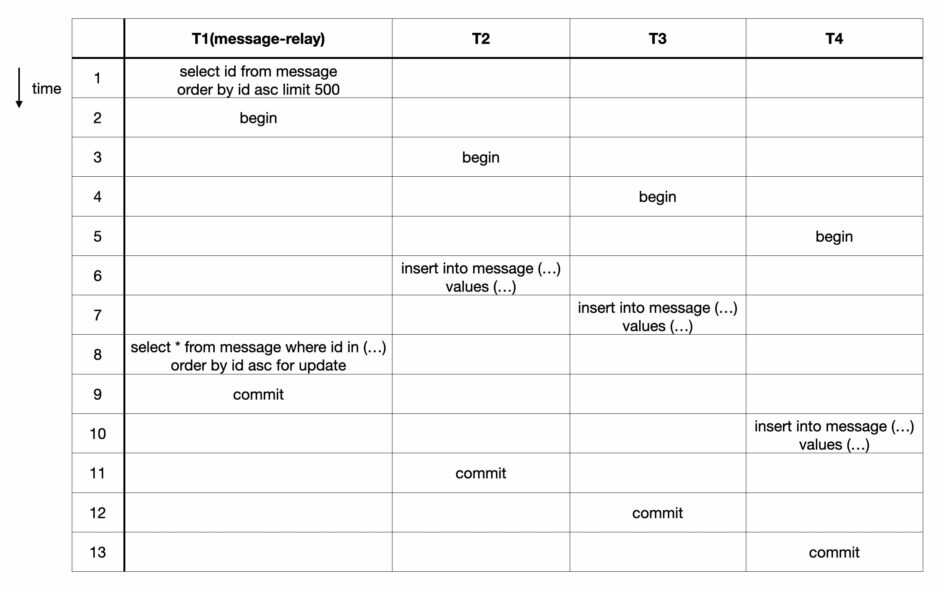
후자에서는 T1에서 이미 commit 된 row를 lock 없이 먼저 조회해서 해당 id에 대해서만 select for update 쿼리를 통해서 lock을 설정합니다. T2, T3, T4에서는 index에 새로운 record를 insert 합니다. 따라서 T1와 T2, T3, T4는 lock을 경합하는 index record가 서로 다르기 때문에 T1의 select for update 쿼리는 다른 transaction이 commit 되기를 기다리지 않습니다.
따라서 다른 transaction에서 가지고 있는 lock을 wait 하지 않는 후자의 방식을 선택하는 것이 처리 지연을 막는 데 안전합니다.
LIMIT의 효과
message-relay는 아래의 방식으로 메시지에 lock을 설정하고 메시지를 삭제합니다.
const queries = {
findMessagesIds: (limit: number) =>
`SELECT * FROM message ORDER BY id ASC LIMIT ${limit}`,
findMessages: (ids: number[]) =>
`SELECT * FROM message WHERE id in ${ids} ORDER BY id ASC`,
deleteMessages: (ids: number[], limit: number) =>
`DELETE FROM message WHERE id in ${ids} ORDER BY id ASC`,
};
const messageIds = await queries.findMessageIds(LIMIT);
await db.transaction(async (trx) => {
const messages = await queries
.findMessages(messageIds)
.forUpdate()
.transacting(trx);
const { publishedMessageIds } = await kafka.publish(messages);
await queries.deleteMessages(publishedMessageIds).transacting(trx);
});때때로 findMessages()와 deleteMessages() 에서 latency가 높게 치솟는 경우가 있었습니다. select나 delete 쿼리들이 단순한 쿼리들이기 때문에 쿼리가 무겁다기보다는 lock wait가 원인일 것으로 생각했습니다. 모니터링을 해보니 동시에 다른 transaction에서 insert 쿼리가 빈번한 상황에서 주로 문제가 발생했습니다. findMessages()나 deleteMessages() 는 이미 commit 된 index record에 대한 lock을 설정하려 하고, 다른 transaction의 insert 쿼리는 새로 추가되는 index record에 대해서 lock을 설정하려 합니다. 얼핏 봤을 때는 둘 사이에 lock 경합이 없어서 문제가 없을 것 같다고 생각할 수 있습니다.
MySQL 8.0부터는 performance_schema.data_locks 테이블을 조회함으로써 현재 어떤 index record에 lock이 설정되어 있는지, 어떤 index record에 대해 lock을 wait 하고 있는지 쉽게 확인할 수 있습니다.
다음 표는 insert 쿼리가 포함된 다른 transaction이 아직 종료되지 않은 상황에서 select * from message where id in (1, 2, …, 499, 500) order by id asc for update 쿼리를 실행했을 때의 performance_schema.data_locks 테이블을 조회한 결과입니다.
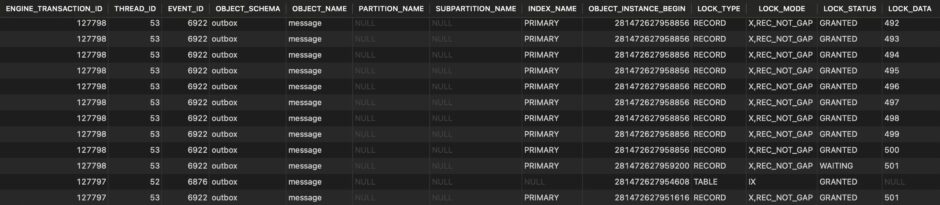
LOCK_DATA column을 보시면 primary key 값이 501인 index record에 insert 쿼리가 lock을 획득했는데, 해당 index record에 select 쿼리가 lock을 wait 하고 있음을 보여줍니다. select 쿼리의 where id in (:ids) 에 501이 없는데도, 501에 해당하는 index record까지 lock을 wait 하고 있었습니다.
해당 현상이 왜 발생하는지 의문이 생겨서 MySQL 공식 문서를 확인해 보다가, 아래 문장이 눈에 띄었습니다.
A locking read, an UPDATE, or a DELETE generally set record locks on every index record that is scanned in the processing of an SQL statement.
select for update와 같은 locking read와 update, delete 쿼리의 경우, query optimizer에 의해서 사용할 index와 query plan이 정해지면 해당 query plan대로 데이터를 조회하면서 scan 하는 모든 index record에 lock이 설정됩니다.
그렇다면 query plan이 중요한 단서가 됩니다. explain analyze를 이용해서 select * from message where id in (1, 2, …, 499, 500) order by id asc for update 쿼리의 실행 계획을 살펴보니 index full scan을 하고 있었습니다.
-> Filter: (outbox.message.id in (1, ..., 500)) (cost=51.2 rows=500) (actual time=0.799..1.04 rows=500 loops=1)
-> Index scan on message using PRIMARY (cost=51.2 rows=500) (actual time=0.275..0.477 rows=500 loops=1)index 전체를 full scan 하면서 index record 전체에 lock을 설정하려고 하니, insert가 쿼리가 lock을 가지고 있는 index record에도 lock을 wait 했던 것입니다.
이제 해야할 일은 index full scan이 발생하는 것을 최소화하고, 최대한 index range scan으로 유도하는 것입니다. 쿼리를 조금씩 바꿔가며 실험을 해보니, order by와 limit을 같이 사용하면서 limit을 where절에 입력되는 ids의 개수보다 1을 작게 넣으면 대부분의 경우 index range scan으로 쿼리가 실행되는 것을 확인했습니다.
select * from message where id in (1, 2, …, 499, 500) order by id asc limit 500 for update-> Limit: 500 row(s) (cost=51.2 rows=500) (actual time=0.0394..0.199 rows=480 loops=1)
-> Filter: (outbox.message.id in (21,22,23,...,518,519,520)) (cost=51.2 rows=500) (actual time=0.0386..0.182 rows=480 loops=1)
-> Index scan on message using PRIMARY (cost=51.2 rows=500) (actual time=0.0289..0.149 rows=500 loops=1)select * from message where id in (1, 2, …, 499, 500) order by id asc limit 499 for update-> Limit: 499 row(s) (cost=51.2 rows=499) (actual time=0.0384..0.307 rows=480 loops=1)
-> Filter: (outbox.message.id in (21,22,23,...,518,519,520)) (cost=51.2 rows=500) (actual time=0.0375..0.289 rows=480 loops=1)
-> Index range scan on message using PRIMARY over (id = 21) OR (id = 22) OR (498 more) (cost=51.2 rows=500) (actual time=0.0362..0.256 rows=480 loops=1)
이 방법을 select for update와 delete 쿼리에 한번 적용해봤습니다. select for update 쿼리의 경우, select * from message where id in (:ids) order by id asc limit ${ids.length - 1} for update 쿼리와 같은 방법으로 실행하고, ids의 가장 마지막 id에 해당하는 row는 다음 while loop에서 처리될 수 있어서 따로 select 하지 않고 다음 while loop에 맡깁니다. delete 쿼리의 경우, kafka에 중복으로 발행되는 것을 막기 위해 반드시 현재의 while loop에서 삭제를 해야합니다. 그래서 쿼리를 다음과 같이 2가지로 나눠서 처리했습니다.
delete from message where id in (:ids) order by id asc limit ${ids.length - 1}
delete from message where id in (:ids[ids.length - 1]) order by id asc limit 1
몇 개월 모니터링을 진행한 결과 lock wait로 인해 쿼리 latency가 이따금씩 치솟는 현상이 사라졌고, 전반적인 쿼리 latency 그래프도 상당히 안정화 된 것을 확인했습니다.
지금까지 공유드린 내용을 적용한 결과, 최종적으로 아래의 코드로 수정됐습니다.
const queries = {
findMessagesIds: (limit: number) =>
`SELECT * FROM message ORDER BY id ASC LIMIT ${limit}`,
findMessages: (ids: number[]) =>
`SELECT * FROM message WHERE id in ${ids} ORDER BY id ASC LIMIT ${ids.length > 1 ? ids.length - 1 : 1}`,
deleteMessages: (ids: number[], limit: number) =>
`DELETE FROM message WHERE id in ${ids} ORDER BY id ASC ${limit}`,
};
const relayMessages = async () => {
const messageIds = await queries.findMessageIdsToPublish(BATCH_SIZE);
if (!messageIds.length) {
return { messages: [] };
}
return db
.transaction(async (trx) => {
const messages = await queries
.findMessages(messageIds)
.forUpdate()
.noWait()
.transacting(trx);
if (!messages.length) {
return { messages: [] };
}
const { successMessageIds, skipMessageIds } =
await publishMessages(messages);
const messageIdsToDelete = sortBy([
...successMessageIds,
...(skipMessageIds ?? []),
]);
if (messageIdsToDelete.length) {
if (messageIdsToDelete.length > 1) {
await queries
.deleteMessages(messageIdsToDelete, messageIdsToDelete.length - 1)
.transacting(trx);
await queries
.deleteMessages(
messageIdsToDelete.slice(messageIdsToDelete.length - 1),
1,
)
.transacting(trx);
} else {
await queries.deleteMessages(messageIdsToDelete, 1).transacting(trx);
}
}
return { messages };
})
.catch((e: any) => {
if (e.code === 'ER_LOCK_NOWAIT') {
return { messages: [] };
}
throw e;
});
}
let shouldTerminate = false;
const terminate = async () => {
shouldTerminate = true;
...
process.exit(1);
}
['SIGTERM', 'SIGINT'].forEach((signal) => {
process.on(signal, () => terminate());
});
while (!shouldTerminate) {
try {
const { messages } = await relayMessages();
...
} catch (err) {
logError(err);
}
}마치며
지금까지 message-relay를 운영하면서 겪었던 문제를 MySQL을 중심으로 개선한 내용을 소개했습니다. MySQL의 lock을 실제적인 측면에서 더욱 깊이 들여다볼 수 있어서 유익한 시간이었고, message-relay를 운영하면서 신경 쓰였던 lock wait와 관련된 문제로부터 벗어나 효과적인 개선이었습니다.
리디 서비스 내에서 점점 Transactional Outbox 패턴을 사용해서 메시지 발행을 보장하려는 경우가 많아지면서 message-relay의 중요성이 나날이 커지고 있습니다. 앞으로도 새롭게 맞닥뜨리는 문제들이 생기겠지만, message-relay의 목표인 ‘메시지의 안전한 발행’을 훌륭히 수행할 수 있도록 지속적으로 개선하겠습니다. 감사합니다.
고객과 발맞춰 새로운 콘텐츠 경험을 선보이는
리디와 함께할 당신을 기다립니다.