이 글은 GTID 기반의 MySQL Replication에 관심있는 Backend 개발자를 대상으로 합니다. 변경 사항을 추적할 수 있는 이력 데이터를 쌓아서 활용해본 개발자라면 아마도 그 일이 얼마나 번거로운지 잘 알고 있을 것입니다. MySQL Replication 라이브러리를 이용하면 DB 자체에 저장되어 있는 변경사항 이벤트를 추출하므로 추가 이력 데이터를 쌓을 필요가 없습니다.
개요
데이터베이스의 Change Data Capture(이하 CDC)는 DB의 변경 이벤트들(Insert/Update/Delete)을 단일 시퀀스 레코드 저장(이하 Append 로그) 방식의 Binary 로그 파일에 저장하고 해당 이벤트들을 스트리밍 방식으로 다른 DB에 복제하는 기술입니다. 요즘은 DB의 CDC를 이용하여 변경 정보를 메시지 큐에 넣고 데이터를 가져와 검색 엔진, 캐시, 통계, 데이터 변경 감사 정보로 활용하는 추세입니다. 왜냐하면 아키텍쳐가 간단하고 구조적으로 데이터 불일치 문제가 없기 때문입니다. 아래 그림은 Martin Kleppmann[1]가 쓴 Logs for Data Infrastructure 라는 글을 참조하였습니다.
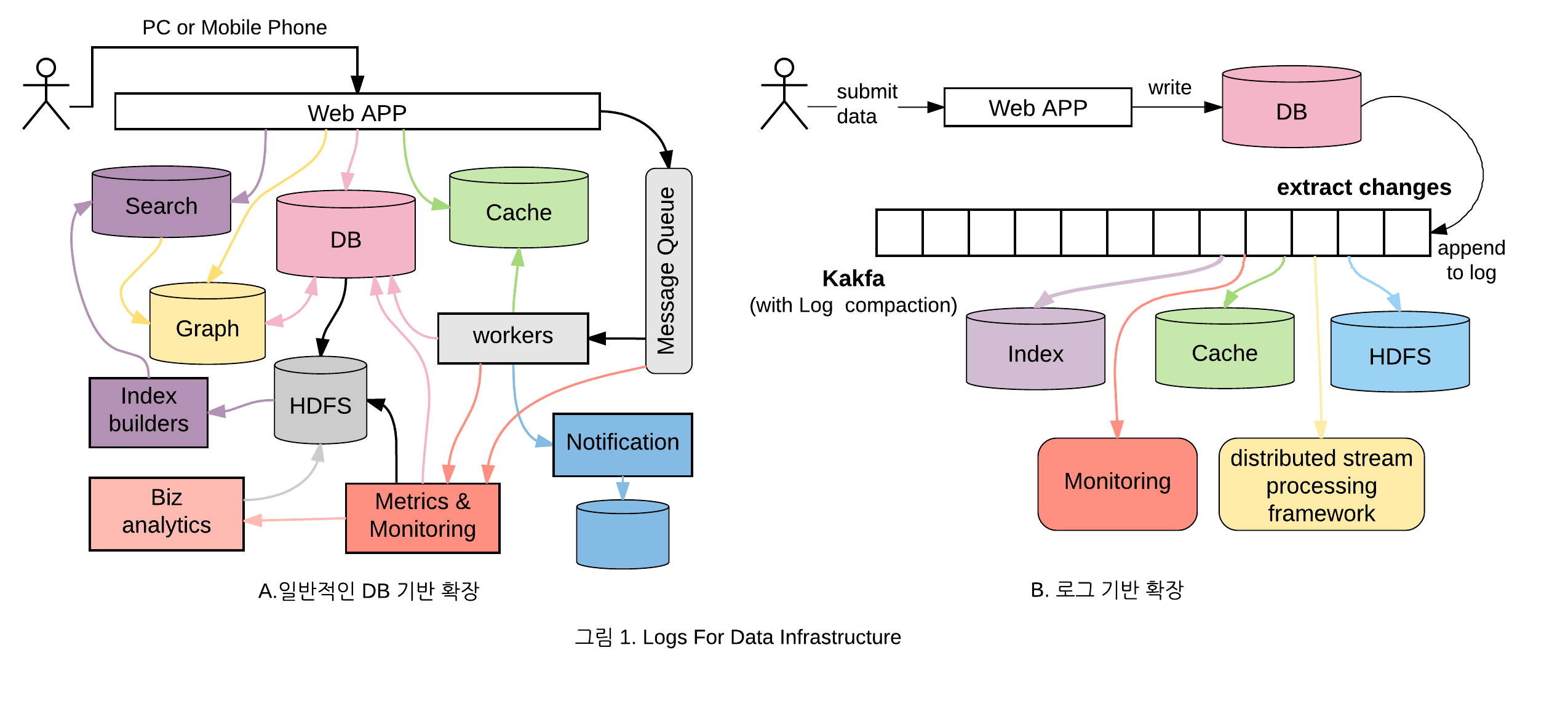
일반적인 DB 기반 구조(왼쪽)는 시스템이 확장될 때 마다 다양한 외부 저장소들이 추가되고, 각 저장소들 간에 서로 데이터를 가져다 사용하므로, 데이터 불일치가 발생하여 시스템이 점점 복잡해집니다. 그러나 로그 기반의 구조(오른쪽)는 CDC 기술을 이용하여 변경 데이터를 추출한 후, 모든 데이터를 일괄적으로 메시지 큐에 넣어서 사용하기 때문에 데이터를 관리하는 입장에서는 단순해집니다. 또한 장애가 발생했을 경우에도 Append 로그 방식의 데이터에서 필요한 위치부터 가져오면 되기 때문에 데이터를 오염없이 활용할 수 있습니다.
전체를 로그 기반으로 확장하는 구조로 변경하기 위해서는 장기적인 관점에서 기술 검토 및 개발 그리고 팀간의 설득 및 협업이 필요합니다. 그래서 범용적인 DB 테이블의 변경 사항 추적 이라는 단일 목적으로, DB의 CDC 기술을 검토하고 기존 환경에서 더 간단한 구조로 활용했던 사례를 공유하겠습니다.
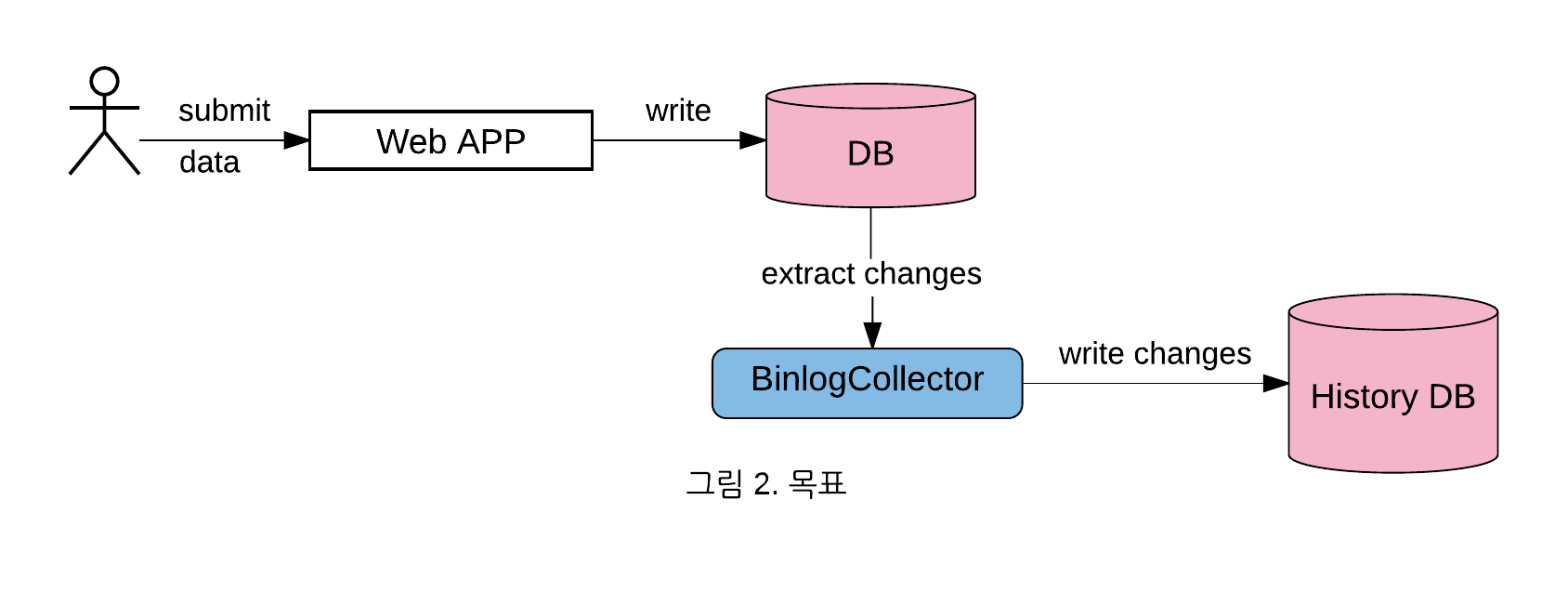
글의 순서는 다음과 같습니다.
- Binlog 분석기의 필요성 및 사용 계기
- 오픈소스 선정 및 요구사항 분석
- Binlog 이벤트 흐름
- Binlog Collector 프로토타입 개발
- 병렬 Binlog Collector 설계 및 개발
- 데이터 분석 완료 시점 조회 및 모니터링
- 성능 측정
- 현재 상황과 앞으로의 과제들
1. Binlog 분석기의 필요성 및 사용 계기
리디 플랫폼팀은 도서의 생명주기(도서수급, 검수, 오픈, 판매중지) 및 도서와 관련된 다양한 정보들(파일, 가격, 태그, …등)을 관리하고 책임지는 플랫폼을 만듭니다. 안정적이고 신뢰성있는 플랫폼을 개발 및 유지보수하기 위해서는, 변경사항을 추적할 수 있는 이력 데이터를 쌓고 필요시에 해당 데이터를 이용하여 문제의 원인을 파악하고 복구하는 일이 중요합니다. 이런 이력 데이터를 만들기 위해서 관계형 데이터베이스(RDB)에서 대표적으로 많이 사용하는 방법은 아래의 표와 같습니다.
| 번호 | 방법설명 | 코드 결합도 | 유지 보수성 | 데이터 추상화 | 데이터양 |
|---|---|---|---|---|---|
| 1 | 테이블 단위의 이력 저장 | Low | Low | Low | High |
| 2 | 서비스 단위로 이력을 모아서 저장 | High | High | High | Low |
| 3 | Binlog 기반의 이력 저장 | X | X | Low | Very High |
각 방법의 장단점을 비교해 정리하면 다음과 같습니다.
- 테이블 단위의 이력 저장
- 장점: 개발이 단순하고, 변경사항이 생길 경우 관련 이력테이블만 수정하면 됨
- 단점: 데이터 추상화가 낮아서 의미있는 데이터를 찾기 위해서는 사용시 외부 Join이 많이 필요
- 사용예: 사용자 테이블의 변경 이력
- 서비스 단위로 이력을 모아서 저장
- 장점: 데이터 추상화가 높아 변경 데이터만 보면 많은 것을 파악할 수 있음
- 단점: 개발이 많이 필요하고, 변경사항이 생길 경우 유지보수에 신경을 많이 써야함
- 일반적으로 변경 이전, 이후의 데이터를 생성하여 서로 비교하여 변경사항을 저장
- 사용예: 도서정보가 변경될 때 그 차이를 저장함
- Binlog 기반의 이력 저장
- 장점: 한 번 수집 환경을 구성하면 최소한의 변경으로 원하는 이력 테이블 추적이 가능
- 단점: 데이터의 양이 막대하고 변경사항 저장에 지연 시간이 존재, 데이터 추상화가 낮음
RDB의 특성상 모든 변경사항(Insert/Update/Delete)이 적용된 최종상태의 정보만 남아 있기 때문에 이력이 필요한 경우 1,2번 방법을 이용하여 별도로 이력을 생성해야 합니다. 특히 현재 사용중인 환경에서 새로운 이력 수집 요구사항이 있을 때, 기존 코드를 수정해야 합니다. 그래서 내부 이력 추적 시스템의 보강을 위해, 앞서 설명한 3번 Binlog 기반의 이력 저장을 생각하게 되었습니다. 모든 변경사항 정보가 Binlog 파일에 이미 들어 있기 때문에, Binlog 복제 프로토콜을 이용하면 현재 작동 중인 프로그램과 관계 없이 테이블의 변경사항 추적에는 유용할 것이라 판단했습니다.
2. 오픈소스 선정 및 요구사항 분석
MySQL Replication 라이브러리들은 다양한 언어(Java/Python/PHP/Node.js/Go)로 포팅되어 오픈소스로 구현되어 있었고, 라이브러리 사용시 주요하게 고려한 사항은 다음과 같습니다.
- 사용 및 권한 제약은 없는가?
- 서버세팅: binlog-format:row 방식 사용
- Client 접근 및 스키마 정보 조회 권한 필요
- REPLICATION SLAVE, REPLICATION CLIENT, SELECT
- Mariadb-10.X 버전 지원
- 필요한 데이터를 추출 할 수 있는가?
- DB에서 Insert/Update/Delete를 할 경우
- TableMap과 Write/Update/Delete 이벤트가 발생
- 테이블 정보(PK IDs, …)
- Write/Delete시 Rows 정보, Update시 이전/이후 Rows 정보
- TableMap과 Write/Update/Delete 이벤트가 발생
- 스키마가 중간에 변경될 경우
- Query 이벤트(쿼리문 포함)가 발생
- DB에서 Insert/Update/Delete를 할 경우
- 특정 위치로 부터 데이터 조회가 가능한가? (장애 발생시, 해당 위치로부터 분석하기 위해서)
- 다음과 같이 2가지로 시작 위치 지정 가능
- Binlog 파일명과 위치(이하 BinlogOffset)
- GTID(Global Transaction ID)
- 범용적인 트랜잭션 ID로 BinlogOffset으로부터 독립적
- MySQL, MariaDB 각각 지원(서로 호환 X)
- 다음과 같이 2가지로 시작 위치 지정 가능
또한 위의 오픈소스 라이브러리를 보완할 수 있는 Binlog 이벤트 관련 쿼리들을 찾아보았는데, DB 복제 기능을 사용해 본 분들이라면 아래의 하위 2개의 Binlog 이벤트 관련 쿼리에 익숙하실 것입니다.
| 쿼리 | 설명 |
|---|---|
SHOW BINLOG EVENTS [IN 'log_name'] [FROM pos] [LIMIT [offset,] row_count] | 특정 Binlog 이벤트들을 조회함 |
SHOW MASTER STATUS | 현재 MASTER의 BinlogOffset을 조회함 |
SELECT BINLOG_GTID_POS (binlog_filename, binlog_offset) | BinlogOffset을 GTID로 변환함 |
Binlog 이벤트 관련 쿼리와 위의 고려사항과 관련된 기능을 테스트해보고, 아래와 같은 방법으로 개발이 가능함을 확인하였습니다.
- MariaDB의 BinlogOffset을 GTID로 변환
- 변환한 GTID를 사용하여 Binlog 이벤트들을 가져옴
- 원하는 테이블의 Write/Update/Delete 이벤트를 가공하여 데이터 추출
- 장애 발생시, 재처리를 위해서 현재까지 처리한 GTID 위치를 트래킹
3. Binlog 이벤트 흐름
특정 GTID를 이용해서, Binlog 이벤트를 가져온다는 것은 확인했지만 실제 사용하기 위해서는 Binlog 이벤트 흐름에 대해서 좀 더 구체적인 이해가 필요 했습니다. 그래서 MySQL 이벤트 문서[2]와 오픈소스 라이브러리를 통해 Binlog 이벤트 흐름을 아래와 같이 정리할 수 있었습니다.
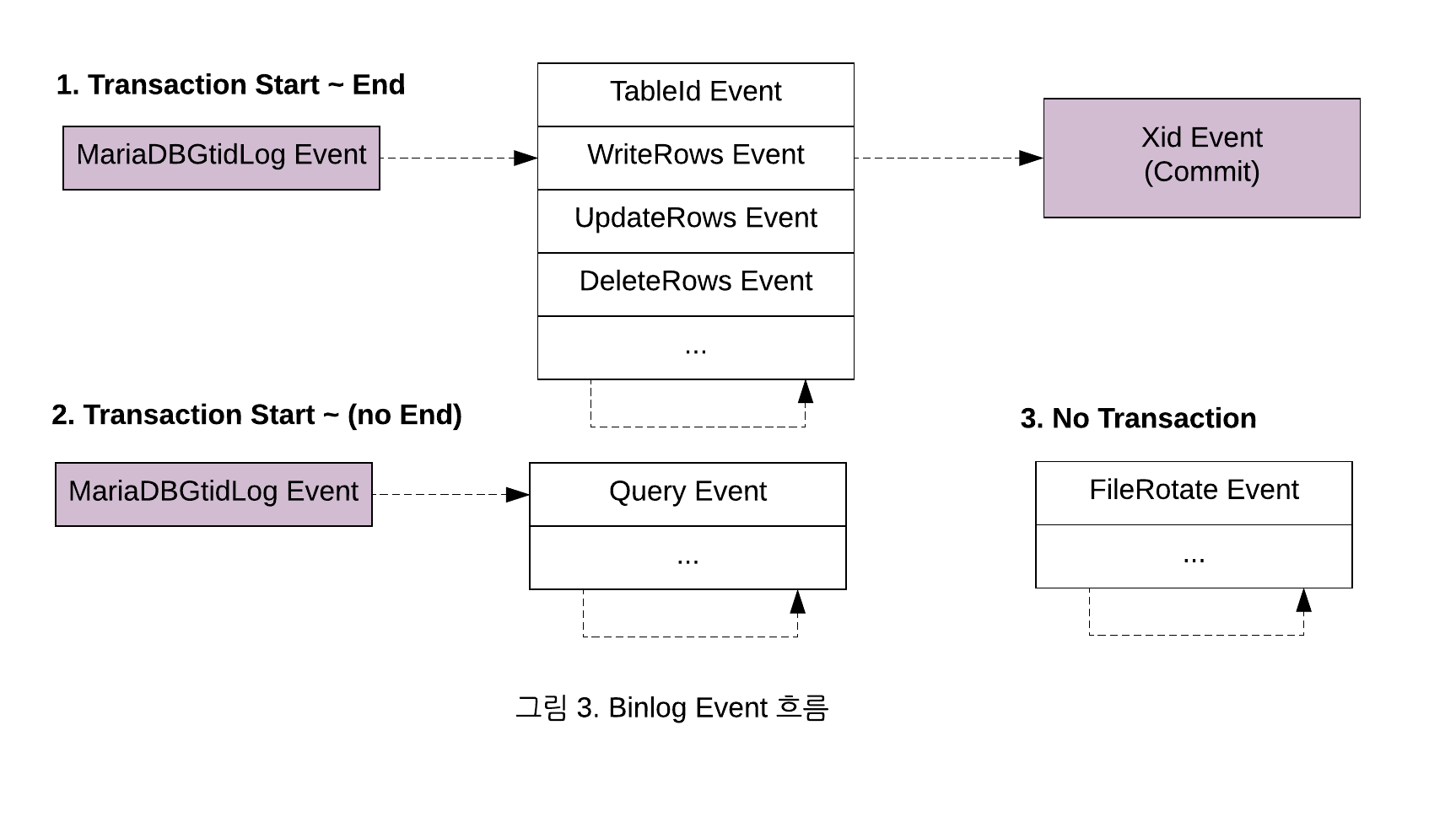
분석이 필요한 Write/Update/Delete 이벤트인 경우는 MariaDBGtidLog 이벤트에서 Xid(Transaction Id = Commit) 이벤트까지 하나의 트랜잭션 단위로 가져옵니다. Query 이벤트는 일반적으로 MariaDBGtidLog 이벤트로 시작하여 Query 이벤트(DDL 문)로 종료됩니다. Binlog 파일의 용량이 다 차서 파일이 변경되면 FileRotate 이벤트가 발생하는데, 해당 이벤트는 MariaDBGtidLog 이벤트 없이 독립적으로 발생합니다.
한편, 특정 GTID 위치로부터 구동하면, 그 다음 GTID의 MariaDBGtidLog 이벤트부터 스트림을 가져오게 되는데(예: 0-1-7140로 시작하면, 다음 0-1-7141부터 가져옴), 그것은 DB Replication이 내부적으로 정상 복제 처리된 경우 해당 GTID를 Commit해 두었다가 다음 복제 시에는 정상 처리된 이후의 GTID로부터 데이터를 가져오도록 설계되었기 때문입니다.
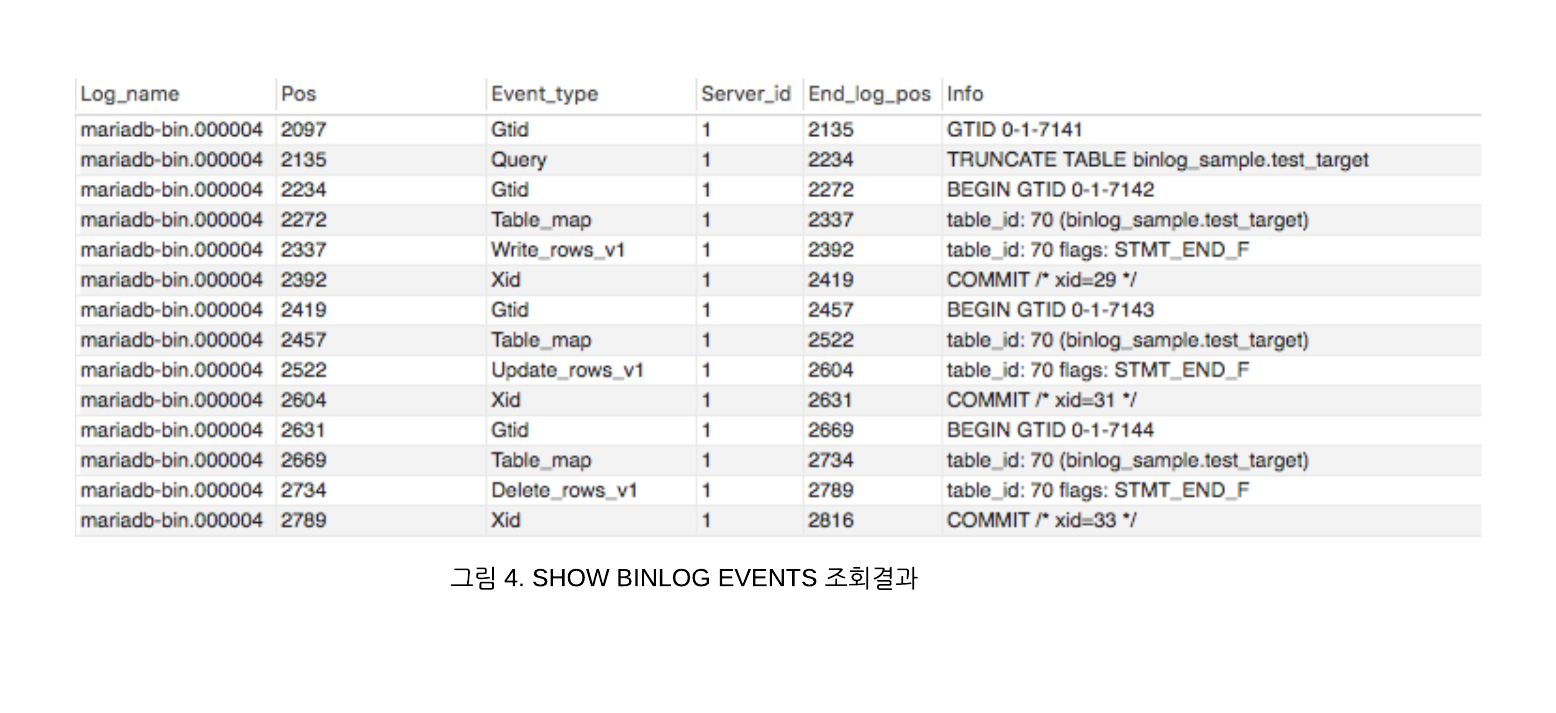
실제 Binlog 이벤트들을 처음 보신 분들이 계실 수 있어서, 샘플 쿼리를 실행 한 후 SHOW BINLOG EVENTS 로 조회한 내용입니다.
TRUNCATE TABLE binlog_sample.test_target;
INSERT INTO binlog_sample.test_target (data, admin_id) VALUES ('insert_data','test_id');
UPDATE binlog_sample.test_target SET data = 'update_data' WHERE admin_id = 'test_id';
DELETE FROM binlog_sample.test_target WHERE admin_id = 'test_id';
4. Binlog Collector 프로토타입 개발
분석한 내용을 토대로 Binlog를 분석하여 수집, 저장하는 Binlog Collector를 아래와 같이 설계 했습니다. 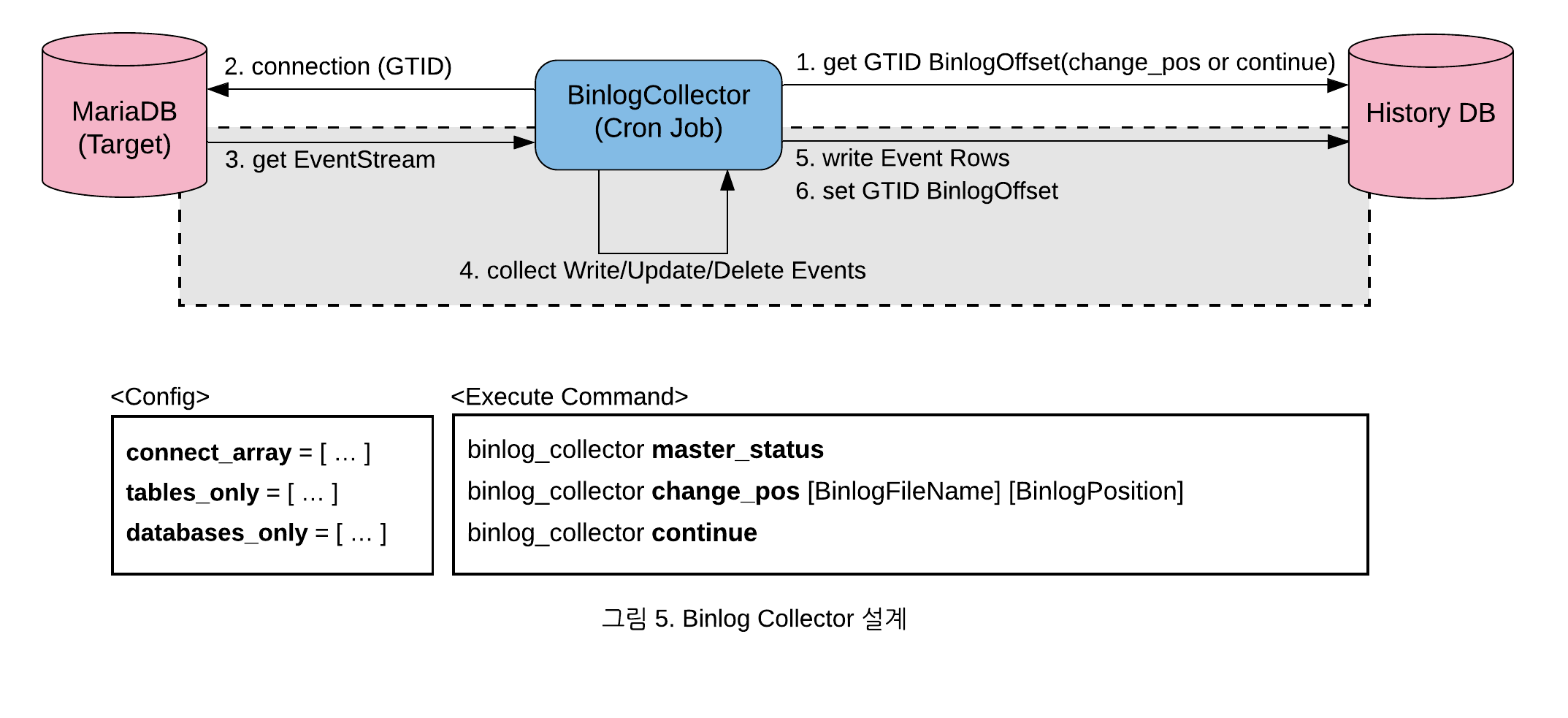
자세한 동작 방식은 다음과 같습니다.
- 최초에 수집할 Binlog 위치 정보가 없기 때문에 change_pos를 사용하여 최초 BinlogOffset을 설정
- master_status로 타겟 DB의 현재 BinlogOffset 조회 가능
- 해당 BinlogOffset을 GTID로 변환하여 타겟 DB에 연결
- Binlog 이벤트 스트림을 연결 – 입력한 GTID의 다음 GTID부터 시작
- 이벤트 스트림을 처리하여, Write/Update/Delete Rows를 수집
- 모아진 이력 Rows를 JSON 데이터로 저장
- 현재 GTID 위치를 DB로 업데이트
- 4-6 과정을 반복
- 단, FileRotate 이벤트가 발생하면 현재 Binlog 파일명을 다음 파일명으로 변경
이후에 Cron으로 Binlog Collector의 continue로 계속 실행하도록 설정하면 마지막 수집 시점 이후 변경 내용을 계속 수집 할 수 있습니다. 위와 같이 간단한 방법으로 프로토타입을 개발했지만, 실제 적용해 보니 다양한 문제점들이 발생하였는데, 크게 6가지였습니다.
- 불필요한 분석 데이터가 많음
- 해결: 특정 조건에 맞는 데이터만 수집하도록 예외 처리 추가
- 예) 가격 테이블의 삭제만 수집
- 해결: 특정 조건에 맞는 데이터만 수집하도록 예외 처리 추가
- 한 GTID 안의 대량의 데이터 처리 문제
- 한 트랜잭션 안에서 대량의 데이터가 있어서, 메모리 오류 발생
- 데이터 이관으로 인한 대량 Bulk insert 시 발생
- 테이블 구조 변경으로 인한 전체 Update 시 발생
- 해결: 한 트랜잭션 안에서 설정된 개수의 이벤트 데이터만큼 쪼개서 저장
- 한 트랜잭션 안에서 대량의 데이터가 있어서, 메모리 오류 발생
- 분석 완료된 BinlogOffset의 잦은 갱신으로 인한 DB 오버헤드
- 해결방안연구:
- 메모리 Table을 사용하면 장애시 휘발성
- 외부 DB를 사용하면 구조가 복잡해짐
- 해결: 분석완료된 BinlogOffset의 갱신을 설정된 GTID 개수(예: 500개)마다 실행
- 따라서 장애가 발생할 경우, 재처리시 중복 데이터 허용
- 수집 데이터가 Append 로그 방식이기 때문에 중복이 발생해도 사용하는 쪽에서 보정이 쉬움
- 해결방안연구:
- Binlog TableMap 이벤트의 테이블 ID 매핑 문제
- 테이블 ID를 조회해 보니 DB에 존재하지 않았고, 실제 Binlog 복제시에 내부 테이블 정보 캐쉬용 ID임[3]을 알게 됨
- 해결: 테이블 ID 대신 테이블명을 저장하도록 수정
- 시작시 Binlog 파일명을 못 찾는 문제
- 시작 GTID와 다음 GTID 사이에 File Rotate 이벤트가 있으면 구동시 파일명을 못 찾음
- File Rotate 이벤트는 GTID 밖에 존재하기 때문에(그림3. Binlog 이벤트 스트림) 구동시 다음 GTID부터 이벤트를 가져올 때 File 변경 이벤트는 무시되므로, 처음에 입력한 Binlog 파일명의 변경을 알지 못함
- 해결: 처음 실행시, GTID 계산이 실패할 경우 Binlog 파일의 다음 시퀀스 파일명을 계산하여 보정
- 예) maraidb-bin.000044 → maraidb-bin.000045,
maraidb-bin.999999 → maraidb-bin.000000
- 예) maraidb-bin.000044 → maraidb-bin.000045,
- 시작 GTID와 다음 GTID 사이에 File Rotate 이벤트가 있으면 구동시 파일명을 못 찾음
- 다중 GTID 환경의 BinlogOffset에서 GTID 변환 문제
- MariaDBGTIDLog 이벤트(domainID, sequenceNumber, flag)에는 서버 ID가 포함되어 있지 않아서 따로 ID를 기억하여 조합하여 GTID를 직접 계산
- 단일 GTID: {domainID}-{serverID}-{sequenceNumber}
- 멀티 GTID 환경인 경우 하나 이상의 GTID가 섞여 있으므로, MariaDBGTIDLog 이벤트가 발생할 때 어떤 서버 ID로부터 오는지 추적이 힘듦
- 해결: GTID를 직접 계산하지 않고 항상
SELECT BINLOG_GTID_POS쿼리를 이용하여 변환하도록 수정
- MariaDBGTIDLog 이벤트(domainID, sequenceNumber, flag)에는 서버 ID가 포함되어 있지 않아서 따로 ID를 기억하여 조합하여 GTID를 직접 계산
위의 문제를 해결하고 실제 상용에 적용해보니, Binlog Collector가 추적하고자 하는 테이블은 적으나 불필요한 테이블에 대한 데이터를 거르는데 시간이 너무 많이 걸려서 Master의 현재 위치를 따라 잡지 못하고 계속 지연되는 현상이 발생하였습니다. 성능 저하의 원인은 나중에 파악하고, 우선 Binlog 파일이 Append 로그 방식의 데이터 구조라서 분할 정복(divide and conquer)이 쉬운구조로 판단되어, 바로 병렬처리로 설계하게 되었습니다.
5. 병렬 Binlog Collector 설계 및 개발
DB 복제를 위한 Binlog 이벤트 스트림은 태생적으로 GTID 기반으로 범위를 나누어서, 서로 영향 없이 개별적으로 분석하여 데이터를 쌓기에 최적화 되어 있는 구조이므로 분할 정복이 가능합니다. 그래서 Binlog Collector를 ‘작업할 영역을 쪼개는 Partitioner’ 와 ‘각각에 대해 Child Process가 해당 영역을 분석하고 적재하는 Worker’ 로 변경하였습니다.
1) BinlogCollect Partitioner를 설계한 그림은 다음과 같습니다.
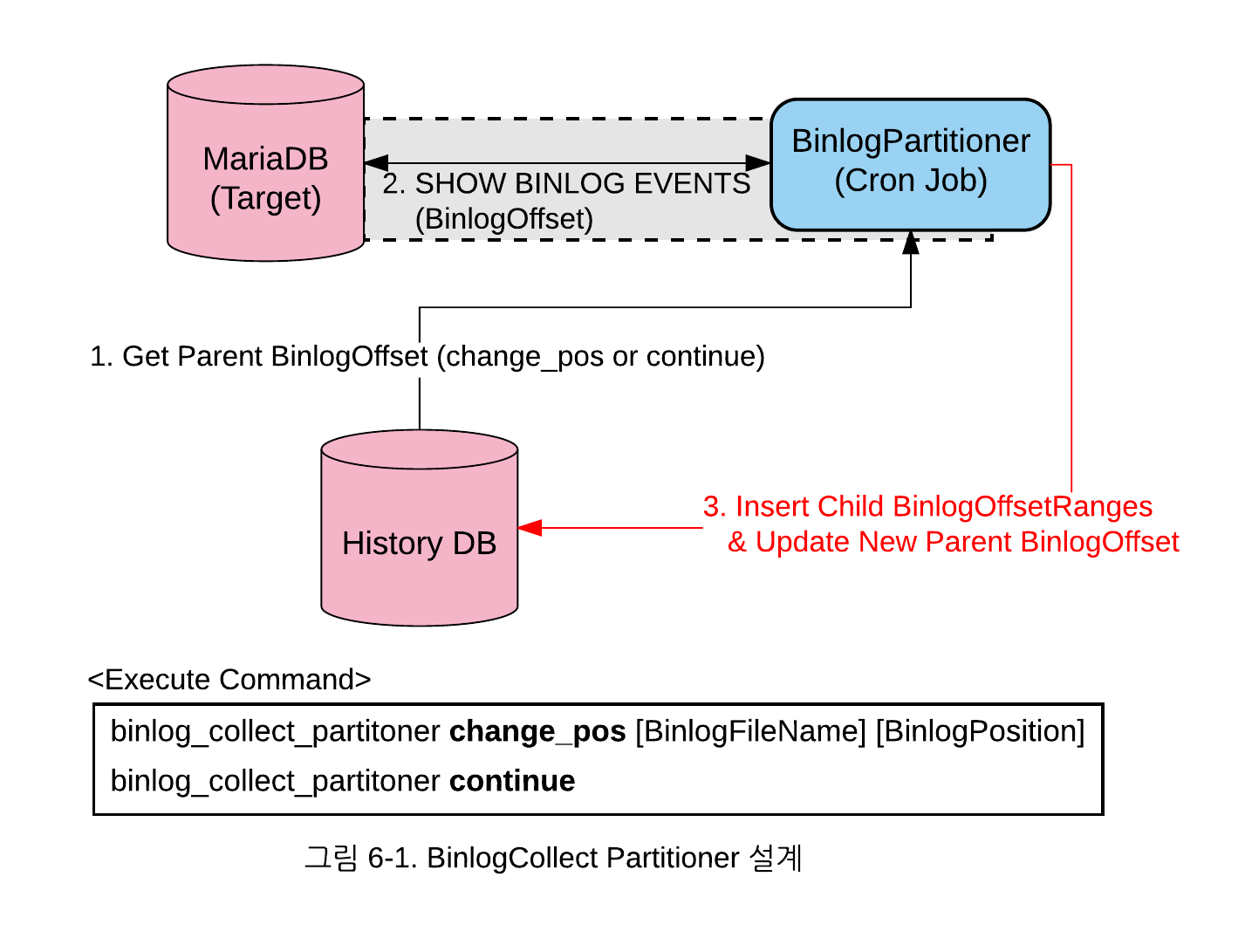
파티셔닝은 1) 최종적으로 분석하거나, 새롭게 입력받은 위치로부터(Parent BinlogOffset) 2) SHOW BINLOG EVENTS를 반복 사용하여 이벤트를 조회하여, 3) 설정된 GTID 개수만큼 Child BinlogOffsetRanges들 만큼 나누게 되는데, 구체적으로 나누는 예는 다음과 같습니다. 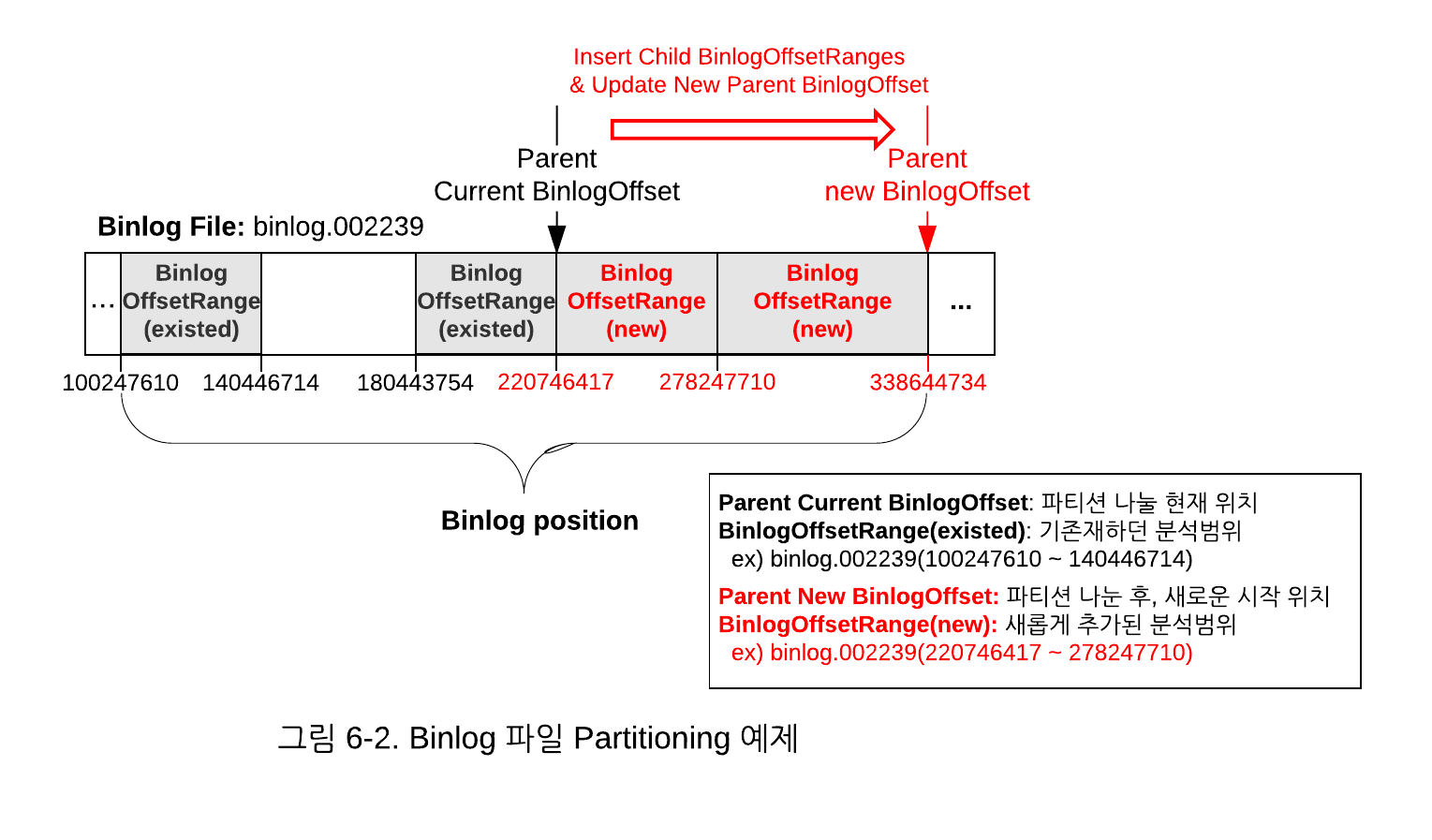
2) BinlogCollect Worker를 설계한 그림은 다음과 같습니다.
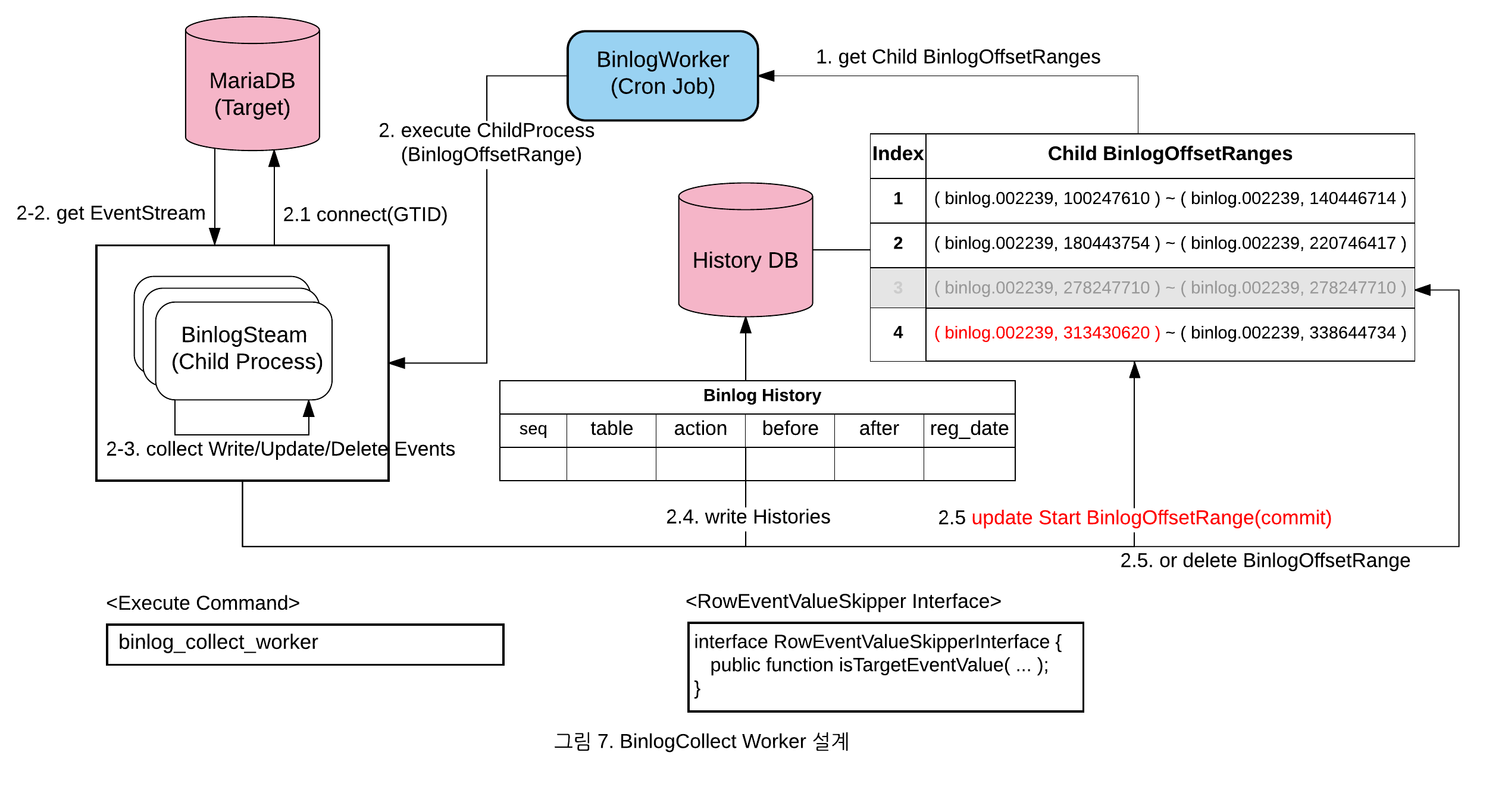
자세한 동작 방식은 다음과 같습니다.
- 수집할 Child BinlogOffsetRanges를 조회
- 정해진 수만큼 Child Process를 생성하며, 각각 독립적으로 아래 과정을 거침
- 해당 BinlogOffsetRange의 시작 위치를 사용하여 타겟 DB에 연결
- Binlog 이벤트 스트림을 연결
- MariaDBGTIDLog 이벤트와 트랜잭션 ID 이벤트 사이의 데이터를 모음
- 관심없는 Rows들은 무시(RowEventValueSkipperInterface 구현체 사용)
- 수집한 데이터를 가공하여 저장
- 다음 조건에 따라 분석을 계속하거나 종료
- 설정된 개수(ex:500개)의 GTID를 지날 때마다 BinlogOffsetRange의 시작 부분을 갱신
- 분석 완료 Commit
- End에 도달하면, 해당 BinlogOffsetRange의 Row를 지우고 종료
- 설정된 개수(ex:500개)의 GTID를 지날 때마다 BinlogOffsetRange의 시작 부분을 갱신
- 2.3-2.5 과정을 반복
이런 구조로 Binlog Collector를 개발하여 수집을 해 보았습니다. 그런데 설계시 예상하지 못한 몇가지 문제가 발견 되었습니다.
- Partitioner 분할 범위가 커짐에 따라 속도 저하
SHOW BINLOG EVENTS가 검색 기능이 없으므로, 분할 범위가 커짐에 따라 GTID 이벤트를 세는데 오버헤드가 커짐- 해결: 아래의
LIMIT를 이용해서 시작 위치부터 설정된 ROW 개수만큼 이동 후에 나오는 첫번째 GTID의 BinlogOffset으로 파티션을 나눔SHOW BINLOG EVENTS [IN 'log_name'] [FROM pos] [LIMIT [offset,] row_count]- GTID 개수로 정확하게 분할하던 기존 방법에 비해서 불필요한 연산이 줄어들어 빠름
- 상용에서 GTID 변환(
SELECT BINLOG_GTID_POS) 속도 저하- 상용환경에서 분석하고자 하는 테이블이 소량임에도 Master의 현재 위치를 따라 잡지 못하고, 계속 차이가 벌어지는 현상이 발생
- Binlog 파일이 클수록 GTID 변환 쿼리 속도가 느려지는 것을 발견
- 테스트 환경과 상용 환경의 Binlog 파일 사이즈가 달라서 빠르게 파악 하지 못함
- 테스트:100M, 상용:1000M
- 해결: 필요시에만 최소한으로 GTID를 변환하도록 변경
- 저장된 이력 로그 검색의 어려움 및 중복 데이터 처리의 불편
- 타겟 테이블의 이력 Rows의 Before/After JSON 정보를 그대로 DB에 넣었지만, JSON이라 이력 로그 조회가 불편
- 해결: 이력 적재 테이블을 binlog, row, column으로 테이블을 정규화하여 적재하고, 정규화 적재를 할 때 바로 사용할 수 있도록 중복 데이터도 제외하도록 수정
6. 데이터 분석 완료 시점 조회 및 모니터링
실제 업무에서 Binlog 기반으로 데이터 변경사항을 추적하다보니, 실시간은 아니더라도 특정 시간 이내에 데이터 분석이 완료되었는지 보장해줄 필요성이 있었습니다. 예를 들어 한 시간 단위로 판매불가로 바뀐 도서에 대한 무결성을 체크하여 이상시 메일로 알리는 기능을 제공해야할 때 Binlog Collector가 5분의 지연 시간을 보장해준다면 매시 6분 이후에 체크하면 됩니다.
따라서 지연 시간 보장을 위해 현재까지 분석된 BinlogOffset에 발생 시간을 함께 추가하려고 했으나 파티션을 나누기 위해 조회한 SHOW BINLOG EVENTS의 결과에는 아쉽게도 날짜 정보가 포함되어 있지 않았습니다. 대신 DB 복제 프로토콜에는 이벤트 발생 시간 정보가 포함되어 있어서, 파티션을 나눌때 각각의 시작 위치에 대한 Binlog Collector를 구동하여 다음 GTID의 첫번째 이벤트 시간을 넣었습니다.
Partitioner와 Worker를 통한 BinlogOffset에 데이터 분석 시간을 보장할 수 있도록 개선한 그림은 아래와 같습니다.
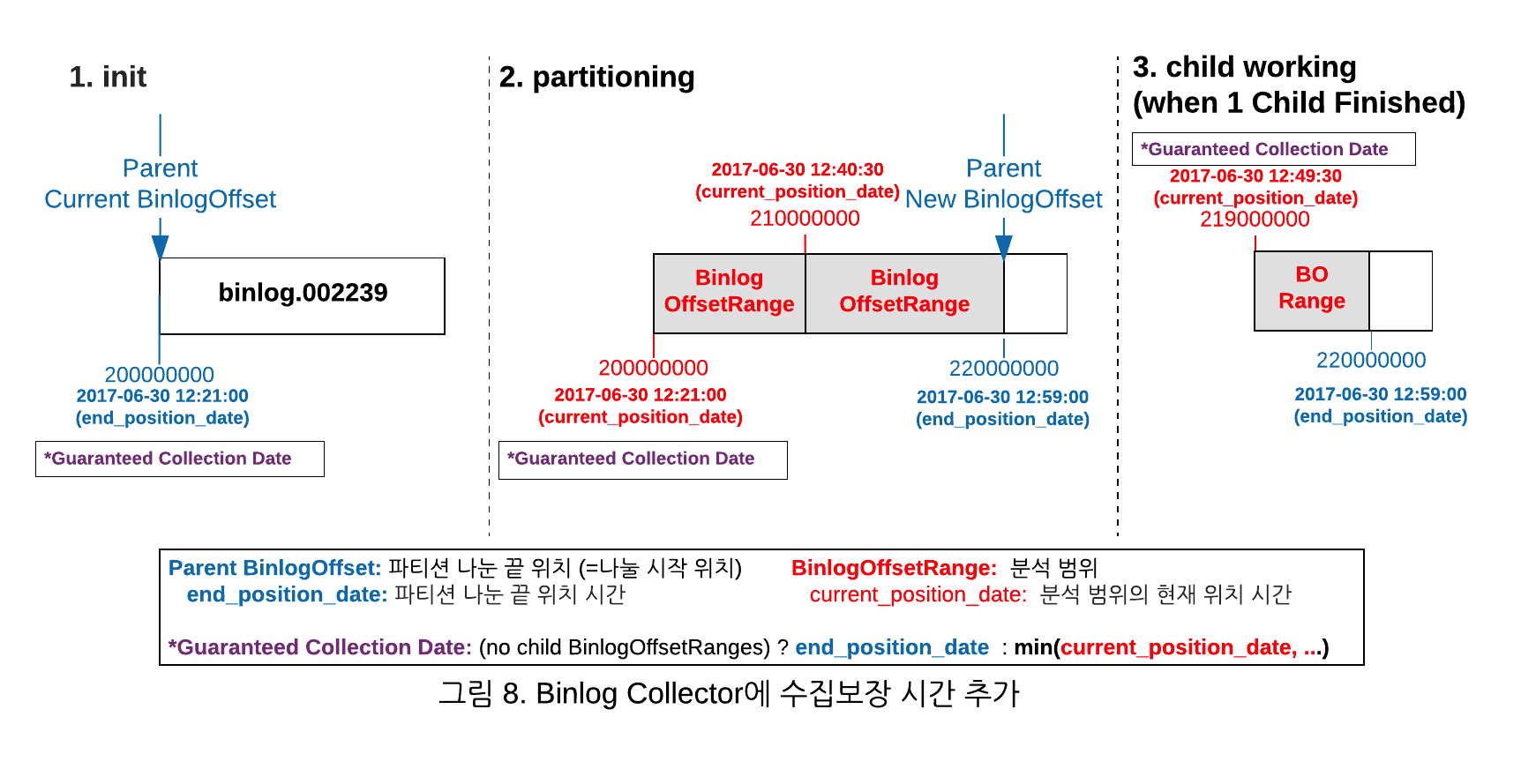
위의 그림에서 보는 것처럼 분석 보장 시간은 아래와 같습니다.
1. Child 분석 범위가 없으면, Parent의 end_position_date (그림 1번)
(처음 시작일 때 또는 Child 분석 범위가 모두 완료되어 전부 삭제된 경우)
2. Child 분석 범위가 있으면, Child 중 가장 오래된 curent_position_date (그럼 2,3번)
추가적으로 지연 모니터링은 Partitioner와 Worker가 정상적으로 동작 중인지 그리고 현재 시간 기준으로 지연이 얼마 이상되면 알려줄 수 있도록 Sentry와 메일을 활용했습니다.
실제 지연 모니터링은 좀 더 복잡하고(예: DB의 변경사항이 발생하지 않아서 10분 째 데이터 변경사항이 없는 경우), 개선해야될 내용(예: 멀티 GTID 환경에서 master 2대가 번갈아서 계속 변경이 발생하는 경우)이 더 있지만 여기에서 간단하게 마무리하려고 합니다.
7. 성능 측정
대략 얼마만큼의 속도가 나올지 궁금해 하실 것 같습니다. 블로그를 쓰는 현재 공개할 수 있는 것은 도서를 관리하는 플랫폼 상용환경에서 22개의 테이블을 추적하며, 20개의 Worker로 현재 지연시간 5분 이내 목표치를 가지고 정상 운영 중에 있습니다. 그래도 실제 성능이 궁금하실 것 같아서 간단한 테스트 환경을 만들어서 성능을 측정해 보았습니다.
- 테스트 테이블 생성
예) CREATE TABLE binlog_sample.test_target ( id int NOT NULL AUTO_INCREMENT, -- size: 4bytes [4] data VARCHAR(255), -- size: 1bytes + data bytes data2 VARCHAR(255), -- size: 1bytes + data bytes admin_id VARCHAR(255) -- size: 1bytes + data bytes ); ... - 100개씩 대량 Insert로 800번 실행하여 800,000 건의 데이터 생성
예) INSERT INTO binlog_sample.test_target (data, data2, admin_id) VALUES ([200bytes data], [200bytes data], [10bytes admin_id]'), ...; ...- 대량 Insert 100개씩 1건: (4 + 201 + 201 + 11) * 100 = 41,700 bytes
- 전체 Insert 크기: 41,700 * 800 = 33,360,000 bytes
- 실제 Binlog 크기: 34,789,200 bytes
- SHOW BINLOG EVENTS로 계산
- 생성한 데이터를 각 쿼리당 100건의 row씩 변경하는 쿼리 800 건
예) UPDATE binlog_sample.test_target SET data = `200bytes 데이터` WHERE admin_id IN ('admin_00001'); ...- Update 100개씩 1건: 417 * 100 * 2(before/after) = 83,400 bytes (before/after)
- 전체 Update 크기: 83,400 * 800 = 66,720,000 bytes
- 실제 Binlog 크기: 69,549,200 bytes
- 수정한 데이터에 대해서 각 쿼리당 100건의 row을 삭제하는 쿼리 800 건
예) DELETE FROM binlog_sample.test_target WHERE admin_id IN ('admin_00001'); ...- Delete 100개씩 1건: 417 * 100 = 41,700 bytes
- 전체 delete 크기: 41,700 * 800 = 33,360,000 bytes
- 실제 Binlog 크기: 34,789,610 bytes
이를 순차적으로 실행하고 Binlog Collector 분석 테이블을 절반으로 설정하였습니다.
분석 완료 후 예상되는 데이터는 다음과 같습니다.
| 종류 | 개수 | 계산식 (Insert + Update + Delete 개수) |
|---|---|---|
| binlog | 1,200 | ( 800 + 800 + 800 ) / 2 |
| row | 120,000 | ( 80,000 + 80,000 + 80,000 ) / 2 |
| column | 360,000 | ( 80,000 * 4 + 80,000 * 1 + 80,000 * 4 ) / 2 |
이것을 기준으로 실제 분석을 돌려보았고 테스트 환경 및 설정값은 다음과 같습니다.
테스트 환경:
MacBook Pro/A1502
CPU: Intel Core i5 2.7 GHz
SSD: 128GB
Memory: 8 GB
Docker 컨테이너 3대: mariadb:10.0.27 db-master, db-slave, db-slave-slave
db-slave를 읽어서 db-slave-slave에 이력 로그 저장
Partitioner에서 범위를 나누기 위한 Binlog Jump Rows = 10000
동시 실행 worker 개수 = 10 (테스트: 1,2,4,10)
한 GTID 안에서 이벤트를 묶어서 저장할 개수 = 100
분석 완료 범위 Commit을 위한 GTID 개수 = 500
| 동시 실행 개수 | 총 걸린 시간 | 가장 오래 걸린 Worker 시간 |
|---|---|---|
| 1개 | 100s | 14s |
| 2개 | 60s | 16s |
| 4개 | 54s | 21s |
| 10개 | 54s | 54s |
(Partitioner 실행 시간: 1~2s로 동일)
결론적으로 Worker 개수가 증가함에 따라 총 걸린시간이 균등하게 줄지는 않았습니다만, 총 소요시간이 의미있게 감소되었음을 확인 할 수 있었습니다. Docker 컨테이너 기반으로 테스트 환경을 구축해서 쉽게 검증할 수 있는 구조로 만들어 놓았기 때문에 계속 테스트 하며 문제를 해결하고 개선할 예정입니다.
8. 현재 상황과 앞으로의 과제들
현재 Binlog 기반 이력 로그는 이력 테이블이 없거나, 변경 사항 추적이 중요한 일부 테이블, 그리고 중요 데이터의 무결성 체크를 위해서 사용하고 있습니다. Binlog 기반 변경사항 추적은 내부적으로 점점 많이 사용할 것으로 예상하고 있습니다. 이에 따라서 Binlog 수집에 대한 모니터링도 더 강화할 필요도 있고, 좀 더 빠른 처리시간 보장과 대용량 처리를 위해서 데이터를 바로 DB에 적재하는 방식이 아닌, Kafka와 같은 외부 메시지 큐를 이용해서 좀 더 범용적인 방법으로 이력 로그를 쌓고, 대용량 데이터 처리를 위해 Avro나 Thrift와 같은 Binary 포맷으로 데이터를 저장하는 구조에 대해서도 검토해야 할 것 같습니다.
다만 모든 것이 다 되는 만능 도구의 허상을 좇는 것이 아니라, 회사에서 특정한 한 업무에 도움을 주는 유용한 도구로 계속 성장해 나갔으면 하는 개인적인 바람이 있습니다. 소스는 현재 GitHub에 공개되어 있습니다. 부족하지만 긴 글 읽어주셔서 감사합니다.
참고자료
[1] Martin Kleppmann는 캠브리지 대학에서 분산 시스템 리서쳐로 활동하며 다양한 분산 시스템 관련 글을 썼습니다. 특히 Designing Data-Intensive Applications의 저자로 잘 알려져 있습니다.
[2] MySQL 이벤트 문서(이벤트 종류와 이벤트 클래스와 유형)에는 Binlog 이벤트와 타입들이 설명되어 있습니다.
[3] How is the tableID generated?
[4] Data Type Storage Requirements
리디 기술 블로그
고객과 발맞춰 새로운 콘텐츠 경험을 선보이는
리디와 함께할 당신을 기다립니다.