안녕하세요, 리디의 데이터 엔지니어링 파트장 오혜성입니다. 웹툰·웹소설 독자에게 볼 만한 작품을 골라주는 리디의 추천 시스템은 꾸준히 발전하며 비즈니스 기여도를 높여나가고 있습니다.
오늘은 이 과정에서 겪은 문제 해결 경험과 앞으로의 방향성을 여러분께 공유하고자 합니다. 본론에 들어가기에 앞서 리디 추천 시스템의 발전 과정을 간략히 소개하겠습니다.
리디 추천 시스템은
어떻게 발전했나
2022년 리디는 더 나은 품질의 추천 서비스를 제공하고자 추천 시스템을 딥러닝 기반으로 전환했습니다. 기존의 탄탄한 데이터 파이프라인 위에서 필요한 기능을 추가 구현하는 방식으로 접근하여 단기간에 목표를 달성할 수 있었습니다.
2023년에는 딥러닝 기반 추천 시스템을 더 다양한 추천 도메인으로 확장하기 위해 Feature Store를 구축했습니다. 이를 통해 필수적인 비즈니스 및 전처리 로직의 일관된 적용으로 데이터 품질이 향상되었고, 다양한 도메인을 대상으로 한 신규 모델의 빠른 릴리스가 가능해졌습니다.
그 후, 리디 추천 시스템은 운영 상의 이슈와 맞물려 더 높은 수준을 충족해야 할 필요를 맞닥뜨렸습니다. 그러기 위해서는 재정비가 필요하다고 느껴 다음의 목표와 세부 과업을 설정했습니다.
목표: 고객이 접하는 거의 모든 제품 탐색 경로에서 개인화된 동적 추천 경험 제공
- 개발 도구 간소화로 비용 절감
- 모델 버전 관리 및 가시성 확보
- 학습과 추론의 분리 및 롤백 자동화
- 실시간 추론 도입
먼저 목표를 실현하는 데 도움이 될 만한 도구들을 탐색했습니다. 그중 관리형 MLOps 플랫폼인 AWS SageMaker가 우리의 모든 요구사항을 충족할 수 있다고 판단하여, 개념 증명(PoC) 후 도입을 시작했습니다. SageMaker가 구체적으로 어떤 문제를 해결해 주었는지 사례를 통해 소개하겠습니다.
Managed MLOps Platform에 올라타기
첫째, 개발 도구 간소화로 비용 절감
팀의 한정된 개발 리소스로 더 넓은 범위의 업무를 효율적으로 수행하려면 우선순위가 낮은 업무를 줄이는 것이 급선무라고 판단했습니다. 우선, 모델 개발 사이클의 4단계에서 각각 사용 중인 도구들은 다음과 같습니다.
- 단위 테스트 작성 – absl, bazel
- 모델별 설정 작성 – gin-config
- 실험(미세 조정 포함): 학습 및 추론 작업 실행
- 도커 이미지 배포 – bazel, ECR
- 학습 및 추론 실행 – bazel, EKS
- GPU 인스턴스 프로비저닝 – Karpenter, Bottlerocket
- GPU 할당 – Nvidia device plugin, Nvidia Container Toolkit
- 모니터링 및 디버깅 – Kibana, K9s, Datadog
이중 특히 3번 실험 단계의 개발 도구에서 발생하는 이슈가 가장 큰 문제였습니다. 예를 들어보겠습니다.
- 로컬 이미지 빌드 및 EKS Job 실행에 사용하는 bazel docker, k8s rule이 deprecated 됨
- Bottlerocket AMI 버전업 이후, 해당 버전의 Cuda driver와 Nvidia device plugin 기존 설정 값이 호환되지 않아 pod가 GPU 리소스를 할당받지 못하는 버그
- 학습이 종료되었지만 Pod가 Terminating phase로 넘어가지 않는 버그
이런 문제에 낭비되는 리소스를 줄이고자 SageMaker Training 을 도입했고, 개발 사이클 중 3번 실험 단계의 기술 스택을 다음과 같이 간소화할 수 있었습니다. 결과적으로 ML Engineer가 비즈니스와 더 밀접한 엔지니어링 작업에 집중할 수 있게 되었습니다.
- 도커 이미지 배포:
Bazel, ECR ⇒ Bash 스크립트(다른 프로젝트와 공유) + ECR - 학습 및 추론 실행:
Bazel, EKS⇒ SageMaker SDK (+ 관리형 인프라) GPU 인스턴스 프로비저닝 – Karpenter, BottlerocketGPU 할당 – Nvidia device plugin, Nvidia Container Toolkit
참고로 SageMaker Experiments를 활용하면 모델 미세 조정(Fine-tuning) 과정에서 각 시도(trial)별 다양한 지표를 한눈에 시각화하고 비교할 수 있어 모델 성능 최적화 및 실험 관리에 큰 도움이 됩니다. 커스텀 딥러닝 모델을 SageMaker와 연동한 과정에 대해서는 첨부된 링크로 설명을 대신하겠습니다. 아래는 Training 을 실행하기 위한 스크립트 예시입니다.
with exp_run.Run(
experiment_name=config.exp_name,
run_name=config.run_datetime,
sagemaker_session=sagemaker_session,
):
...
est = estimator.Estimator(
image_uri=config.image_uri,
source_dir=config.source_dir,
environment=config.env_vars,
instance_count=config.instance_count,
instance_type=config.instance_type,
output_path=config.output_path,
sagemaker_session=sagemaker_session,
...
)
est.fit(
wait=config.wait,
job_name=config.job_name,
)현재 개발 환경에 적용한 뒤에는 운영환경 역시 Airflow EksPodOperator에서 SageMakerTrainingOperator 로 점차 이관하고 있습니다.
둘째, 모델 버전 관리 및 가시성 확보
모델의 종류와 버전 수가 증가함에 따라 이를 효과적으로 관리하고 모니터링할 필요성이 대두되었습니다. 이에 대응하기 위해 배포된 모델들의 메타데이터를 중앙에서 관리할 수 있는 SageMaker Model Registry를 도입했습니다.
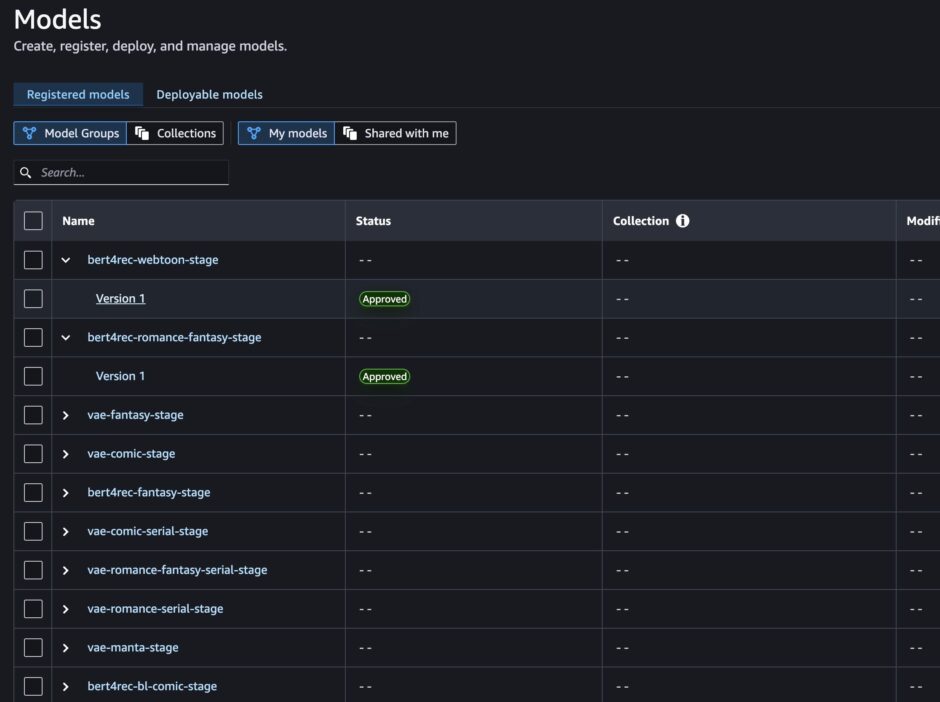
학습 후 검증된 모델의 경우, 아래와 같이 필요한 모델의 메타 정보를 모델 저장소에 등록하게 됩니다.
# the model checkpoint
model_url = "s3://your-bucket-name/model.tar.gz"
modelpackage_inference_specification = {
"InferenceSpecification": {
"Containers": [
{
"Image": image_uri,
"ModelDataUrl": model_url
}
],
"SupportedContentTypes": [ "application/json" ],
}
}
create_model_package_input_dict = {
"ModelPackageGroupName" : model_package_group_name,
"ModelApprovalStatus" : "PendingManualApproval",
...
}
create_model_package_input_dict.update(modelpackage_inference_specification)
create_model_package_response = sm_client.create_model_package(**create_model_package_input_dict)
model_package_arn = create_model_package_response["ModelPackageArn"]
print('ModelPackage Version ARN : {}'.format(model_package_arn))모델 등록 과정은 실험 환경(로컬)에서는 선택 사항이며, 운영 환경에서는 Airflow SageMakerModelOperator를 래핑하여 구현했습니다. 저희 팀의 경우, 새로운 모델 버전 등록 시 기본 승인 상태로 설정하여 추론 시 기존과 같이 새로 학습된 모델 체크포인트를 사용하도록 했습니다. 향후에는 학습된 모델의 목표 지표를 검증하여 임곗값 이하로 떨어지면 거부(reject)하는 단계를 필요에 따라 추가할 계획입니다.
셋째, 학습과 추론의 분리 및 롤백 자동화
(1) 학습과 추론을 분리하기
모델 학습 및 추론 파이프라인은 기본적으로 Airflow에서 배치로 스케줄링되고 있습니다.
Operator에 필요한 의존성은 아래와 같이 데이터클래스로 정의했습니다. 기존에는 학습과 추론 런타임에 필요한 정보를 동일하게 정적으로 주입했습니다. 추론 시 항상 직전에 새로 학습한 모델 체크포인트를 사용하는 구조였습니다.
TRAIN_JOB = job.MLJob(
job_id=utils.get_ml_job_id(_MODEL, predict=False),
config_file=utils.get_model_config_path(_MODEL),
input_table=...,
output_table=...,
base_params=ml_base_config.BaseGinParam(
TRAIN=True,
PREDICT=False,
MODEL_NAME=_MODEL,
...
),
...
)
PREDICT_JOB = job.MLJob(
job_id=utils.get_ml_job_id(_model, predict=True),
config_file=utils.get_model_config_path(_MODEL),
input_table=...,
output_table=...,
base_params=ml_base_config.BaseGinParam(
TRAIN=False,
PREDICT=True,
MODEL_NAME=_MODEL,
...
),
...
)이 같은 구조는 학습과 추론이 강하게 결합되어 확장성이 떨어지는 문제가 있었습니다. 문제를 개선하기 위해 학습과 추론 단계 사이에 모델 등록 단계를 추가했습니다. 그로써 추론 시에 직전 학습 모델을 무조건 사용하는 대신, 모델 리포지토리에서 가장 최근에 승인된 모델을 사용하도록 변경했습니다.
추론 작업에서는 아래와 같이 모델 레지스트리에서 가장 최근에 승인된 모델 체크포인트를 사용합니다.
@property
def _ckpt(self):
...
ckpt = self._base_params.MODEL_CHECKPOINT_PATH or job_utils.fetch_model_checkpoint(
model_package_name=self._base_params.MODEL_PACKAGE_GROUP,
region=self._region,
role_arn=self._assume_role_arn,
)
...
return ckpt
...
# job_uilts.py
def fetch_model_checkpoint(model_package_name: str, region: str, role_arn: str) -> str | None:
sm_client = boto3_conn.get_boto3_conn(region_name=region, role_arn=role_arn).sagemaker
...
response = sm_client.list_model_packages(
ModelPackageGroupName=model_package_name,
ModelPackageType="Versioned",
ModelApprovalStatus="Approved",
)
packages = response["ModelPackageSummaryList"]
if not packages:
logger.error("No approved model versions found for the specified model package group.")
return None
latest_approved = max(packages, key=lambda x: x["CreationTime"])["ModelPackageArn"]
response = sm_client.describe_model_package(ModelPackageName=latest_approved)
return response["InferenceSpecification"]["Containers"][0]["ModelDataUrl"]학습과 추론 단계를 분리함으로써 보다 유연하고 확장성 있는 구조로 개선할 수 있었습니다. 예를 들어 이전에는 학습과 추론을 항상 한 세트로 묶어서 실행해야 했지만, 이제는 어떤 상황에서든 원하는 모델의 정보를 모델 리포지토리에서 참조하여 모델 추론만 독립적으로 실행할 수 있게 되었습니다.
(2) 모델 롤백 자동화
모델 리포지토리를 중간에 두고 모델 학습과 추론을 분리한 결과, 분명한 이점을 얻었습니다. 먼저 배포된 최신 모델의 상태를 ‘approved’에서 ‘reject’로 변경하면, 시스템이 자동으로 직전 모델을 사용하도록 설정되어 추가 비용 없이 롤백 기능을 구현할 수 있습니다.
또, 기존에는 온라인 성능이 임곗점 이하로 떨어질 경우 대응할 수 있는 수단이 거의 없었습니다(S3 체크포인트를 수동으로 수정하는 방법은 있었지만, 이는 이상적인 해결책이 아니었습니다). 이제는 권한을 가진 담당자가 배포된 버전을 거부(reject)하고, 이후 추론 작업만 재실행하면 빠르게 1차 대응할 수 있는 안전장치를 갖추게 되었습니다. 필요하면 해당 과정 전체를 자동화 할 수도 있습니다.
넷째, 실시간 추론 도입
앞서 언급했듯 리디는 모델 추론을 배치로 스케줄링하고 있습니다. 하지만 배치 스케줄링으로 모델을 서빙하면 크게 두 가지 제약이 발생합니다.
먼저, 어떤 사용자가 요청할지 모르기 때문에 가능한 모든 사용자에 대해 추론을 수행해야 합니다. 이는 서비스 사용자 수가 증가함에 따라 선형적으로 증가하는 비용입니다. 그러나 배치로 추론하게 되면 실제로 요청하지 않을 사용자에 대해서도 추론해야 해서 자원 낭비입니다. 사용자별로 아이템 차원 크기에 해당하는 추천 결과를 업로드하는 것에도 물리적 제약이 있어, 사용자별로 상위 200개 아이템만 선별하여 업로드하는 데 따르는 아쉬움도 있습니다.
또한, 다음 추론 결과가 업로드될 때까지 사용자는 동일한 작품을 추천받습니다. 실제로 추천 결과가 업로드된 직후에는 CTR(클릭률)과 CVR(전환율)이 증가했다가 시간이 지나면 다시 감소하는 패턴을 확인할 수 있었습니다.
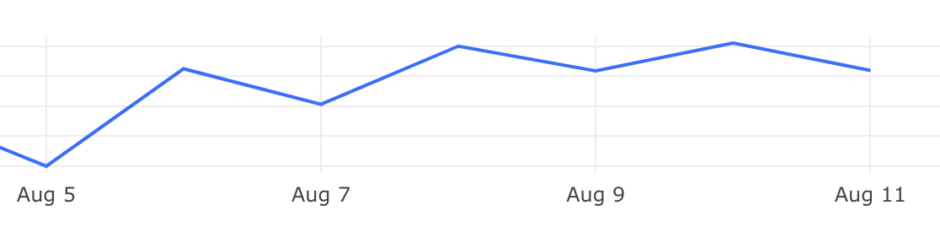
이는 사용자의 탐색 경험 및 리텐션 저하로 이어질 수 있습니다. 따라서 Sequence 기반 모델과 실시간 추론의 시너지를 활용해 조금 더 동적인 추천 경험을 제공할 필요가 있다고 판단했습니다.
(1) PoC
실시간 추론 도입에 앞서 기술적인 검토를 진행했습니다.
(2) Torchserve
SageMaker Real-time inference는 Pytorch Framework 서빙에 기본적으로 TorchServe를 사용합니다. Model Registry에 모델을 잘 등록해두었다면 아래와 같은 스크립트로 간단하게 배포해볼 수 있습니다.
model = sagemaker_model.Model(
image_uri=...,
model_data=...,
entry_point=...,
source_dir=...,
)
model.deploy(
initial_instance_count=...,
instance_type=...,
wait=True,
)하지만 테스트 결과 원하는 수준의 Throughput 과 latency 를 확보할 수 없었습니다. 배포 시 custom inference script 도 필요하니 관련 내용은 링크를 참고하시기 바랍니다.
(3) Tritonserver
Triton Inference Server는 ONNX, TorchScript, TensorRT, Neuron 등 다양한 런타임을 위한 백엔드 프레임워크를 지원합니다. 그중 저희가 테스트한 TensorRT와 Neuron은 각각 NVIDIA GPU와 Neuron device가 탑재된 인스턴스에 특화되어 있습니다. 이들은 사전 컴파일(또는 JIT 컴파일)을 통해 모델 추론을 최적화합니다. 저희는 BERT4Rec 모델을 torch-tensorrt와 torch-neuronx를 사용하여 각각 TensorRT와 Neuron engine이 내장된 TorchScript로 컴파일한 뒤, 실시간 추론을 테스트했습니다.
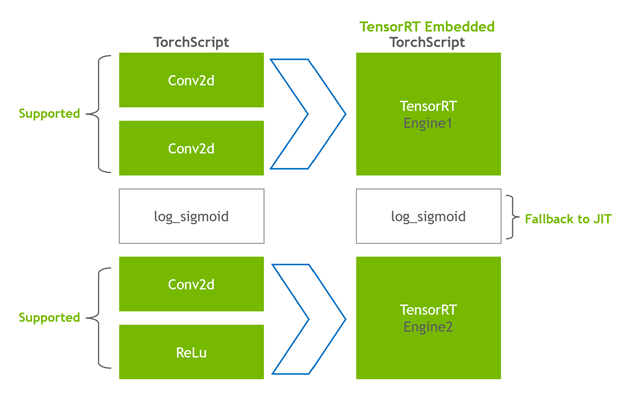
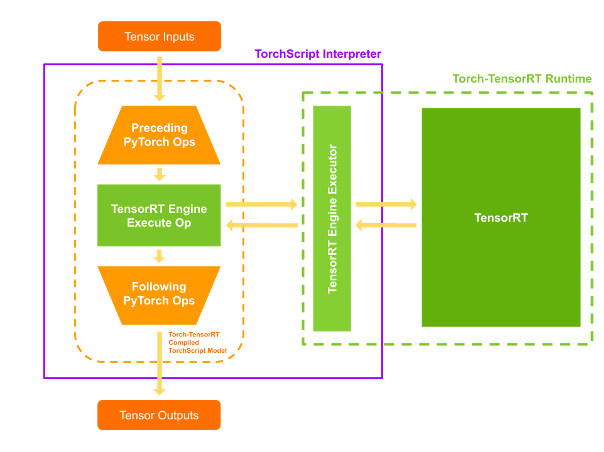
*torch-tensorrt AOT compile 예시
model = model_utils.load_model(
model_checkpoint=_MDOEL_CKPT_PATH,
model_type=models.Bert4rec,
...
)
model.eval()
inputs = [
torch_tensorrt.Input(...),
torch_tensorrt.Input(...),
]
trt_model = torch_tensorrt.compile(
model,
ir="dynamo",
inputs=inputs,
enabled_precisions={torch.half, torch.float32},
truncate_long_and_double=True,
...
)
torch_tensorrt.save(
trt_model,
f"{_MODEL_REPO_PATH}/{_MODEL_NAME}/{_MODEL_VERSION}/model.pt",
output_format="torchscript",
inputs=inputs,
)결과적으로 기존 파이프라인에 쉽게 적용할 수 있는 TensorRT를 채택하였습니다. Neuron 1.x 버전에서는 모델에 사용되는 일부 연산자(operator)들이 지원되지 않는 문제가 있었습니다. Neuron의 경우, 2.x 버전을 사용하려면 Neuron device가 탑재된 인스턴스(Inferentia, Trainium)가 필요합니다. 정확한 시기는 미정이지만 이는 향후 개선될 예정으로 보입니다.
(4) TensorRT on Tritonserver
모델 서빙을 위해서는 입력 데이터 전처리 → 추론 → 후처리 과정이 필요합니다. 예를 들어, 입력에 사용되는 item_id는 인덱싱되어 모델에 입력되어야 합니다 (후처리는 이의 역순). Tritonserver 에서는 그 과정을 위한 모델 앙상블(model ensemble)을 지원합니다.
# bert4ec_ensemble/config.pbtxt 예시
name: "bert4rec_ensemble"
platform: "ensemble"
input [
{
name: "input__0"
data_type: ...
dims: [ ... ]
}
]
output [
{
name: "output__0"
data_type: ...
dims: [ ... ]
},
{
name: "output__1"
data_type: ...
dims: [ ... ]
}
]
ensemble_scheduling {
step [
{
model_name: "bert4rec_preprocessing"
model_version: -1
input_map {
key: "bert4rec_preprocess_input__0"
value: "input__0"
}
output_map {
key: "bert4rec_preprocess_output__0"
value: "preprocess_output__0"
}
output_map {
key: "bert4rec_preprocess_output__1"
value: "preprocess_output__1"
}
},
{
model_name: "bert4rec"
model_version: -1
input_map {
key: "bert4rec_inference_input__0"
value: "preprocess_output__0"
}
input_map {
key: "bert4rec_inference_input__1"
value: "preprocess_output__1"
}
output_map {
key: "bert4rec_inference_output__0"
value: "inference_output__0"
}
output_map {
key: "bert4rec_inference_output__1"
value: "inference_output__1"
}
},
{
model_name: "bert4rec_postprocessing"
model_version: -1
input_map {
key: "bert4rec_postprocess_input__0"
value: "inference_output__0"
}
input_map {
key: "bert4rec_postprocess_input__1"
value: "inference_output__1"
}
output_map {
key: "bert4rec_postprocess_output__0"
value: "output__0"
}
output_map {
key: "bert4rec_postprocess_output__1"
value: "output__1"
}
}
]
}추론 모델 backend는 libtorch, 전/후처리 모델 backend는 python을 사용했습니다. 마지막으로 Triton Performance Analyzer를 사용하여 앙상블 모델의 throughput과 latency를 측정하였습니다.

Tritonserver 에서 지원하는 model configuration 과 모델 추론 구조를 변경해가며 최적의 값을 찾았습니다. SageMaker 는 TorchServe와 마찬가지로 Tritonserver 배포를 지원합니다. 간단하게 배포할 수 있는 과정이니 자세한 설명은 링크를 참고하시기 바랍니다.
(5) CI/CD
실시간 추론 서버 배포를 위한 CI/CD 파이프라인은 아래와 같이 구성하였습니다. Sagemaker MLOps best practice 및 sample guide를 참고하여 상황에 맞게 수정했습니다. 더 자세한 내용은 링크로 대신하겠습니다.
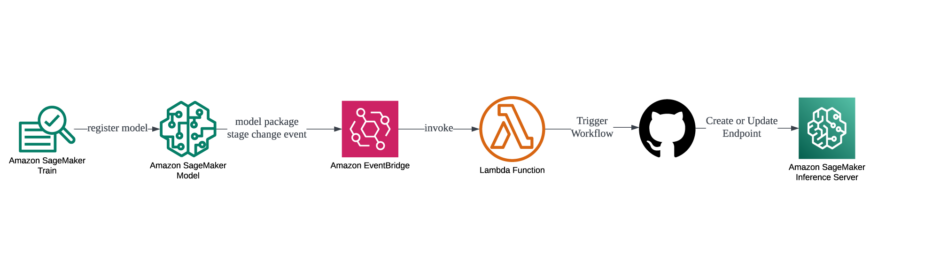
다섯째, TCO 검토
SageMaker 도입을 고려할 때 총 소유 비용(TCO)을 반드시 검토해야 합니다. 저희 팀의 경우, 예를 들어 SageMaker Training, Real-time Inference 등을 활용함으로써 개발 및 운영에 필요한 리소스를 절감할 수 있다고 판단하여 도입을 결정했습니다. 다만, 조직마다 상황이 다르므로 SageMaker 도입 여부를 결정할 때는 다양한 비용을 종합적으로 고려해야 합니다. 직접적인 비용뿐만 아니라 개발 생산성, 운영 효율성, 확장성 등 간접적인 이점도 함께 평가해야 합니다.
앞으로의 과제
앞으로 수행할 과제들도 남아있는데요. 고객에게 동적인 추천 경험을 제공할 수 있도록 실시간 추론 외에도 다양한 방법을 실험할 계획입니다. 또한 인하우스로 개발한 추천 모델 외 다른 도구들도 검토 중입니다. 구체적인 예시를 다음과 같이 소개합니다.
Filtering & Reranking
사용자가 이미 구매한 작품을 블룸 필터(Bloom filter)로 구성하여 추천 목록에서 제외함으로써, 새로운 작품에 더 많은 노출 기회를 제공할 수 있습니다. 현재는 관계형 DB 유저 구매기록 테이블을 활용하고 있지만, Redis Stack bloom filter를 이용해 보다 자원 효율적으로 다양한 시그널별 Bloom filter를 구성할 수 있습니다.
사용자에게 노출되거나 조회되었지만 장기간 구매로 이어지지 않은 작품을 타임스탬프 기준으로 정렬된 집합(sorted set)으로 구성하여, 해당 작품을 후순위로 미루는 재정렬(reranking)을 적용할 수 있습니다. 리디는 사용자 로그를 Kafka를 통해 실시간으로 전송하고 있기 때문에, 이를 활용한 파이프라인을 구성할 수 있습니다.
더불어, 아이템에 대한 사용자별 점수를 기반으로 검색 결과를 최적화하는 방법도 고려하고 있습니다. 예를 들면 높은 점수를 받은 작품을 검색 결과 상위에 노출시키는 전략을 시도해 볼 수 있습니다. 이는 Elasticsearch의 Learning to Rank에서 소개된 개념을 서빙 단계에서 유사하게 구현하는 접근법입니다.
재정렬을 적용하려면 아무래도 사용자별 추천 아이템의 범위를 기존 200개 보다 더 확대할 필요가 있었습니다. 이를 위해 실시간 추론을 선행 작업으로 진행하고 있습니다. 참고로 AWS Personalize 에서도 re-ranking 을 위한 recipe 가 지원되니 이를 활용해 볼 수도 있습니다.
Vector Search
BERT4Rec 모델을 활용하여 사용자와 아이템의 임베딩 벡터를 학습하고 추출할 수 있습니다. 예를 들어, 아이템 임베딩은 모델의 입력층에 위치한 임베딩 레이어에서 얻고, 사용자 임베딩은 모델의 마지막 은닉 상태(hidden state)를 활용할 수 있습니다. 이때 CLS 토큰 임베딩을 사용하는 것이 일반적입니다. 그 후 두 임베딩을 샴 네트워크에 통과시켜 두 입력 간의 유사성을 학습합니다.
이 과정을 통해 얻은 사용자와 아이템 임베딩은 동일한 잠재 공간에 위치하게 되어, 둘 간의 코사인 유사도(cosine similarity)를 계산할 수 있습니다. 이는 사용자-아이템 간 관련성을 효과적으로 측정하여 작품 추천 및 캠페인 타켓팅에 활용될 수 있습니다.
지금까지 리디 추천 시스템을 고도화하기 위한 핵심 과정과 향후 과제를 소개했습니다. 다양한 시도와 구현을 거치며 리디의 작품 추천 시스템은 더욱더 견고해지고 있습니다. 요즘처럼 취향이 세분화되고 다양한 콘텐츠가 쏟아져 나오는 때, 독자가 원하는 작품에 쉽고 정확히 닿을 수 있도록 리디의 추천 시스템이 쭉 활약할 예정입니다. 이상으로 글을 마치겠습니다. 감사합니다 🙂
Contributors
Data Engineer : 오혜성, 안수현
고객과 발맞춰 새로운 콘텐츠 경험을 선보이는
리디와 함께할 당신을 기다립니다.