안녕하세요, 리디 웹 팀 프론트엔드 엔지니어 김요한입니다. 저는 2022년 리디의 연말 대형 이벤트를 개선하는 과정에서 얻었던 경험을 여러분과 공유하고자 합니다.
1. 마크다운 이벤트
2. 작품을 빠르게 그릴 방법
31만 개가 넘는 엘리먼트를 최적화하기
가상화의 대가를 치르기
3. 작품을 빠르게 “불러올” 방법
gzip을 켜보기
필터링을 하는 동안 스켈레톤을 보여주기
잘못된 필터링 로직을 수정하기
잘못된 필터링 로직이 느린 이유
4. 마크다운 이벤트를 마치며
1. 마크다운 이벤트
보통 마크다운이라고 하면, 대부분의 엔지니어 분들께서는 Markdown 마크업 언어를 먼저 떠올리실 것 같습니다. 그런데 사실 사전을 뒤져보면 마크다운이라는 단어에는 가격 인하라는 뜻이 있습니다. 리디에서는 매년 연말 마크다운 이벤트를 진행하는데요, 이름대로 한 번에 많은 종수의 작품을 할인 판매하는 이벤트입니다.
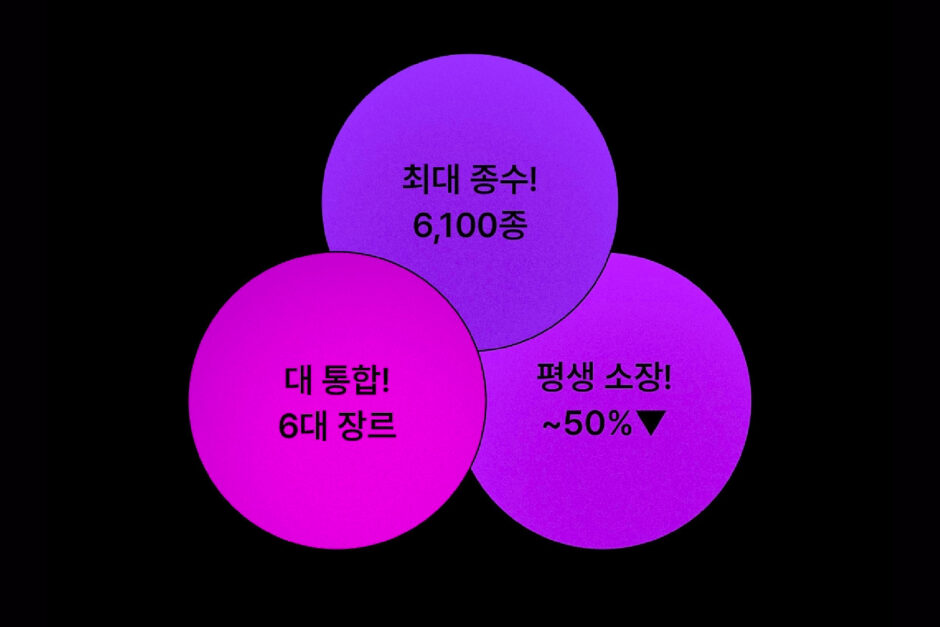
2022년 마크다운 이벤트는 총 6,107개의 작품을 가지고 진행되었습니다. 이벤트를 진행하기 위해서는 당연히 대상 작품들을 보여주는 페이지가 필요했습니다. 이에 대해 막연히 기존에 사용하고 있던 이벤트 페이지에 배너 이미지와 작품을 등록하면 될 것이라 생각했는데요.

문제는 이벤트 관리 페이지에 다음 메시지가 적혀있었다는 것입니다.
도서는 250권 이내로 게재해 주세요.
즉, 기존 리디 이벤트 페이지는 6,000개씩이나 되는 콘텐츠를 등록하기 위해 만들어진 페이지가 아니었습니다. 기존 페이지는 250개 작품에 맞춰 설계된 페이지입니다. 저희는 여기에 예상보다 24배 더 많은 콘텐츠를 넣으려고 하고 있습니다.
24배 많은 콘텐츠를 넣어보니, 가장 처음으로 UX 문제가 눈에 띄었습니다. 기존 이벤트 페이지는 스크롤 몇 번이면 모든 작품이 보이는 페이지입니다. 반면 작품이 6,000개씩이나 되면 스크롤이 끝없이 내려갑니다. 그 수많은 작품 중에서 사용자가 원하는 작품을 찾기란 매우 힘들어 보였습니다.
6,000개의 작품 안에는 사용자가 이미 구매했거나, 관심이 없는 장르의 작품 등이 많이 있을 것입니다. 어쩌면 몇 개를 제외한 대부분의 작품에는 관심이 없을 수도 있습니다. 그렇지만 그런 상황에 대한 대응은 하나도 되어있지 않았습니다.
그래서 고객이 겪을 불편함을 해소하기 위해, 저희는 다음과 같은 기능들을 추가하여 이 이벤트 페이지를 6,000개의 작품에 맞는 페이지로 바꾸고자 했습니다.
- 장바구니 기능
- 작품 필터링
- 작품 장르 탭
- 실시간 이벤트 참여 금액
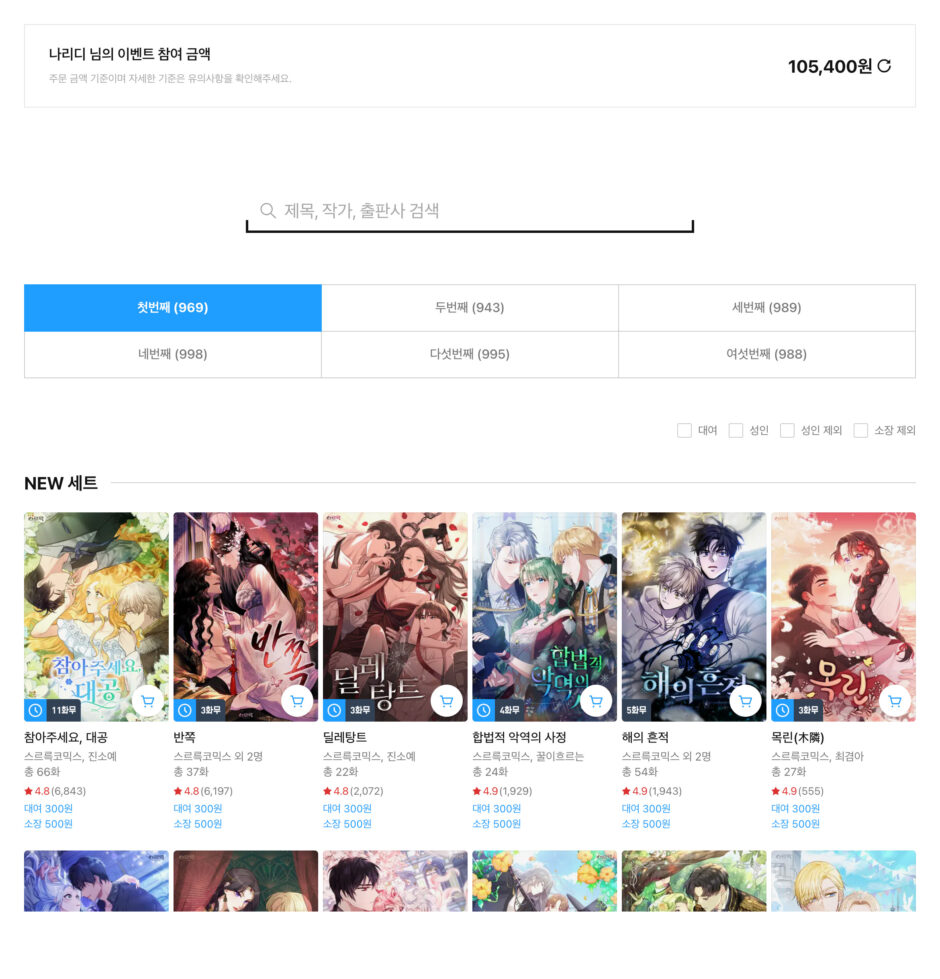
(위 이미지에 포함된 작품 표지는 내용 전달을 위해 임의로 구성하였습니다.)
2. 작품을 빠르게 그릴 방법
기능을 추가하는 것 외에도 저희가 헤쳐나가야 할 또 다른 문제가 있었습니다. 사실 관리 페이지에서는 250개가 한계라고 했지만, 작년 마크다운 이벤트에서는 약 1,000개 정도의 작품을 페이지 하나에 이미 등록해 본 적이 있었습니다. 그리고 그 결과로 다음과 같은 좋지 않은 일들이 일어났었습니다.
- 모바일 (특히 저사양 안드로이드 디바이스)에서는 거의 사용이 불가능할 정도로 느렸습니다.
- 페이지가 그려지는 데에만 10초 넘는 시간이 소요되었습니다.
- 유저가 무려 10MB 이상을 HTML로 받아오고 있었습니다.
1,000개 작품만 가지고도 제대로 이벤트를 진행할 수 없다면, 6,000개 작품으로 진행하는 건 더더욱 어려울 것입니다. 그렇기 때문에 웹 팀에서는 기능 추가와 더불어 해당 페이지를 빠르게 만드는 작업을 시작했습니다.
31만 개가 넘는 엘리먼트를 최적화하기
가장 먼저 기존 이벤트 페이지를 느리게 한 원인을 조사했습니다.
하단의 사진은 예전 이벤트 페이지를 라이트하우스로 분석한 결과 얻을 수 있었던 지표로, 1,000개가 넘는 작품이 한 번에 그려지고 있다는 사실을 확인할 수 있었습니다. 따라서 사용자 입장에서는 60,000개의 엘리먼트를 한 번에 받아서 그리고 있으니 당연히 느릴 수 밖에 없었습니다.

1,000개가 이렇다면 실제 6,000개는 어떨까? 하고 궁금증 반으로 실제 6,000개의 작품을 넣고 document.querySelectorAll('*') 를 찍어봤습니다. 그러자 무려 315,455개의 엘리먼트가 들어있는 것이 보였습니다.
이는 네트워크 비용으로 보나 렌더링 비용으로 보나 쾌적하다는 느낌과는 아득하게 멀리 떨어져 있는 숫자입니다. 그렇기에 이 숫자의 크기를 줄이는 것이 첫 번째 큰 목표가 되었습니다.
그렇다면 이 중에 몇 퍼센트가 실제로 쓸모 있는 엘리먼트일까요?
하단의 스크린샷에서 보면 일반적인 유저의 화면에는 작품이 약 20개 정도밖에 그려지지 않습니다. 6,000개 작품 중에 20개가 그려진다면 약 0.3%만 그려지는 것이고, 이는 97.7%의 작품은 그리지 않아도 무방하다는 뜻입니다.

보이는 콘텐츠만 그리는 것은 흔히들 리스트 가상화, 또는 윈도잉이라 부르는 기법으로 달성할 수 있습니다. 리스트 가상화는 전체 리스트 중에서 보이는 엘리먼트만 렌더링을 하고, 보이지 않는 엘리먼트는 DOM 트리에서 빼버리는 기법입니다.
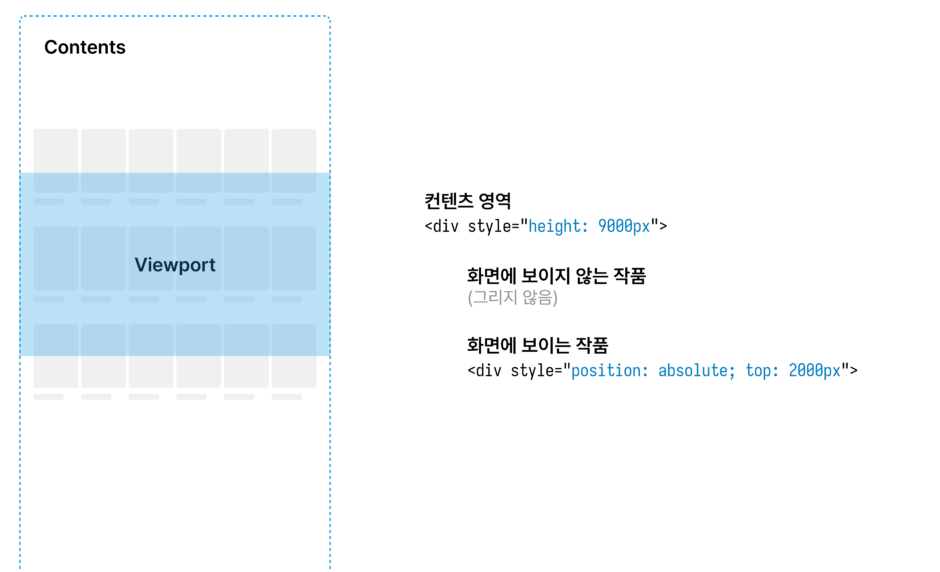
만약 아이템의 높이를 계산할 수 있다면 현재 스크롤 위치에 알맞은 아이템을 알아낼 수 있습니다. 이를 가지고 스크롤 시에 1. 보여야 하는데 그려지지 않은 아이템을 그리고 2. 안 보여도 되는데 그려진 아이템을 지우면 됩니다.
사실 이 기법을 직접 구현하지 않더라도 미리 잘 구현된 라이브러리가 많이 있습니다. 저희는 그중에서 react-virtualized, react-window, react-virtuoso 3가지 라이브러리를 테스트해 보았습니다. 그리고 그중에 유지 보수와 번들 크기, 저희가 쓸 기능이 구현돼있는지 등을 종합적으로 고려해서 react-window를 선택하였습니다.
(아래 첨부한 정보는 2023년 1월 28일 기준입니다.)
| react-window | react-virtualized | react-virtuoso | |
|---|---|---|---|
| 기능 |
크기계산 ×
스켈레톤 △
오버스캔 ◯
window 스크롤 ×
|
크기계산 ◯
스켈레톤 △
오버스캔 ◯
window 스크롤 ◯
|
크기계산 ◯
스켈레톤 ◯
오버스캔 ◯
window 스크롤 ◯
|
| 유지보수 | 되고 있으나 활발하진 않음 (3개월 전 릴리즈) |
거의 되고 있지 않음 (2년 전 릴리즈) |
활발함 (2일 전 릴리즈) |
| 번들 크기 | 6.4KiB | 27.4KiB | 15.5KiB |
| 스타 수 / NPM 다운로드 수 | 13.6k / 1.3M | 24.6k / 1.8M | 3.3k / 0.3M |
특히나 저희는 모든 아이템의 높이를 미리 알고 있고, 많은 기능이 필요하지 않은 상황이었기 때문에 react-window만으로도 충분하다고 판단하였습니다.
한 가지 아쉬운 점으로는, react-window는 자체 엘리먼트의 스크롤과만 연동할 수 있고 window의 스크롤과 연동하는 것을 지원하지 않았습니다. 즉, 페이지는 그대로 있고 react-window 영역만 스크롤 되는 케이스에서만 사용이 가능했습니다.
하지만 직접 연동하는 게 어렵지는 않아, 다음과 같은 코드로 직접 window의 scroll 이벤트를 받아서 동기화하는 방식을 선택하였습니다.
const ref = useRef<ReactWindowRef>(null);
const outerRef = useRef<HTMLDivElement | null>(null);
useEffect(() => {
const handleWindowScroll = () => {
const { offsetTop = 0 } = outerRef.current || { offsetTop: 0 };
const scrollTop = window.scrollY - offsetTop;
if (ref.current) {
ref.current.scrollTo({ scrollLeft: 0, scrollTop });
}
};
handleWindowScroll();
window.addEventListener('scroll', handleWindowScroll);
window.addEventListener('resize', handleWindowScroll);
return () => {
window.removeEventListener('scroll', handleWindowScroll);
window.removeEventListener('resize', handleWindowScroll);
};
}, []);
이렇게 하면 window의 scroll 이벤트가 발생할 때마다 react-window의 scrollTo 함수를 호출해서 react-window가 스크롤을 처리하게 만들 수 있습니다.
이제 반대로 react-window의 자체 엘리먼트가 스크롤 되지 않게 할 차례입니다. 직접 전체 높이를 계산해서 height 스타일을 전체 높이로 줄 경우, 자체 엘리먼트는 스크롤이 일어나지 않게 됩니다.
이렇게 window의 스크롤을 react-window와 연동할 수 있었습니다.
가상화의 대가를 치르기
전체 작품 목록을 가상화해서 테스트해 보니 성능은 비약적으로 빨라졌습니다. 그러나 빠르게 스크롤 할 때 스크롤 속도보다 새로 보이는 아이템을 그리는 속도가 느려 흰 배경이 보이는 문제가 있었습니다. 이 문제를 완화하기 위해서 가상화 라이브러리에서는 스크롤 시 따로 스켈레톤을 그려주는 기능을 제공합니다.
하지만 그 스켈레톤도 DOM으로 그려지기 때문에 메인 스레드의 부담이 커져, 저사양 기기에서는 “흰 배경이 보임 → 스켈레톤이 잠깐 반짝함 → 작품이 보임”의 의도치 않은 결과가 나왔습니다.
(위 이미지에 포함된 작품 표지는 내용 전달을 위해 임의로 구성하였습니다.)
그렇다고 정적인 이미지로 집어넣기에는 스켈레톤이 기기의 너비와 높이에 따라서 크기가 전부 제각각이었습니다. 이 문제를 해결하기 위해서 저희는 스켈레톤의 SVG 코드를 동적으로 생성해서, background-image 와 background-repeat으로 타일링하게 해보았습니다.
const PADDING = 3, THUMBNAIL_RATIO = 223 / 154;
const buildRect = ({ x, y, width, height, fill }: RectOption) =>
`<rect x="${x}" y="${y}" width="${width}" height="${height}" fill="${fill}" rx="4" ry="4" />`;
const useBookSkeleton = () => {
const theme = useTheme();
// 실시간으로 변하는 현재 화면의 크기를 계산해서 스켈레톤의 크기를 반환
const { columnWidth, rowHeight } = useBookListSize();
return useMemo(() => {
let svg = `<svg width="${columnWidth}" height=${rowHeight}` +
` viewBox="0 0 ${columnWidth} ${rowHeight}` +
` xmlns="http://www.w3.org/2000/svg">`;
// 현재 스켈레톤의 크기에 맞는 이미지를 계산해서 썸네일의 스켈레톤을 만듦
const thumbnailWidth = columnWidth - 2 * PADDING;
const thumbnailHeight = Math.round(thumbnailWidth * THUMBNAIL_RATIO);
svg += buildRect(
{
x: PADDING,
y: PADDING,
width: thumbnailWidth,
height: thumbnailHeight,
fill: theme.colors.grey080
}
);
// TODO 썸네일 외의 다른 영역의 스켈레톤을 추가
svg += '</svg>';
return `url(data:image/svg+xml;base64,${btoa(svg)})`;
}, [theme, columnWidth, rowHeight]);
};
export const MyVirtualizerWithSkeleton = ({ children }: { children: ReactNode }) => {
const skeleton = useBookSkeleton();
const style = useMemo(() => ({
backgroundPosition: 'top left',
backgroundRepeat: 'repeat',
backgroundImage: skeleton
}), [skeleton]);
return <MyVirtualizer style={style}>{children}</MyVirtualizer>;
};이렇게 할 경우 브라우저 콘솔로 봤을 때 다음과 유사한 마크업이 나오게 됩니다.
{/* List Virtualizer (with Background) */}
<div style="background-image: url(data:image/svg+xml;base64,PHN2ZyB3a...);">
{/* List Virtualizer Inner */}
<div style="width: 1116px; height: 13472px;">
{/* Virtualized Items */}
<Book />
<Book />
<Book />
<Book />
<Book />
</div>
</div>이 방식으로 했을 때의 성능 외 다른 장점은, 가상화를 수행하는 컴포넌트의 역할을 덜 수 있다는 점입니다. 원래는 각기 다른 관심사인 “스켈레톤을 보여주기” 와 “실제 아이템을 렌더링하기” 를 하나의 컴포넌트가 담당했습니다. 그러나 이렇게 바꾸고 나서는 두 역할을 각기 다른 컴포넌트로 분리할 수 있었습니다. 원래 목표인 저사양 기기에서의 최적화도 달성했으니 일석이조입니다.
(위 이미지에 포함된 작품 표지는 내용 전달을 위해 임의로 구성하였습니다.)
3. 작품을 빠르게 “불러올” 방법
가상화를 통해서 작품의 렌더링은 빨라져 체감상 퍼포먼스는 많이 올랐습니다. 하지만 아무리 빨리 그릴 수 있더라도 그릴 데이터가 없다면 아무것도 그릴 수 없습니다.
처음에 데이터를 가져오는 방식을 정할 때 저희는 기존과 동일하게 무한 스크롤 없이 한 번에 데이터를 불러오는 방식을 선택했습니다. 이는 6,000권이 한 번에 내리기엔 그렇게까지 크지 않다는 판단과, 사용자 또한 추가적인 로딩을 겪지 않게 하기 위해서, 그리고 짧은 개발 기간으로 인해 엔지니어링 공수를 가능한 줄이기 위해서였습니다.
그런데 실제로 6,000권을 받아보니 예상보다 페이로드가 커져서 육안으로도 느려 보이는 것이 보였습니다. 페이로드 크기를 보니 전체 데이터가 8.5MiB 씩이나 나오고 있었습니다.
gzip을 켜보기
JSON의 크기가 크다면 JSON 내 데이터 중복을 줄이고 페이지네이션을 다는 것이 이상적입니다. 그러나 그러기에는 시간이 없으니 더 빠르게 해볼 수 있는 방법을 찾아봅니다. 우선 스테이지 환경만 gzip 압축이 꺼져있다는 사실을 발견했습니다. gzip이 사용하는 Deflate 알고리즘은 중복되는 텍스트를 효과적으로 압축해 내기 때문에 gzip을 사용하면 괜찮지 않을까? 하는 생각을 해보았습니다.
과연 정말로 이 이슈는 gzip이 된다면 무시할 만한 것일까요? 우선 전체 데이터를 시험 삼아 압축해서 압축률을 가늠해 보았습니다.
$ du -kh event-without-compression
8.2M event-without-compression
$ gzip -3 -c event-without-compression | pv -b > /dev/null
969KiB놀랍게도 약 1 / 8의 크기로 압축해 내는 것을 확인할 수 있었습니다. 이 정도면 효과가 있겠다 싶어 스테이지 환경의 gzip이 동작하지 않는 이슈를 고쳐보니 정말로 높은 압축률로 압축되었습니다.
아직 매우 큰 JSON을 파싱한다는 문제는 그대로 있고, 당장 900KiB조차도 작은 양은 아닙니다. 하지만 6,000권에서도 그나마 쓸만한 정도의 랜딩 성능이 나왔기에 일단은 나중에 수정하는 것으로 남겨두었습니다.
필터링을 하는 동안 스켈레톤을 보여주기
초기 랜딩 속도는 그나마 쓸만하였으나, 유저의 동작이 화면에 반영될 때까지 걸리는 시간 (INP) 측면에서는 아직도 체감 퍼포먼스가 매우 나빴습니다.
저희의 상황에 대해 조금 더 설명드리자면, 저희는 Suspense를 통해서 데이터를 불러오고 있습니다.[1] 이미 구매한 작품을 숨기는 체크박스를 눌러 필터링을 하면, 데이터를 다시 불러오고 (그동안 Suspense의 스켈레톤을 보여주고) 다 불러온 후 렌더링 되는 식입니다.
const MyComponent = () => {
const [isFilterEnabled, setIsFilterEnabled] = useState(false);
const [isPending, startTransition] = useTransition();
const onFilterCheckboxChange = useCallback(
({ target: { checked } }: { target: { checked: boolean } }) => {
startTransition(() => setIsFilterEnabled(!checked));
},
[],
);
// 다음 코드는 data가 없다면 throw fetch(...) 를 수행합니다
const { data } = useBookDataQuery({ isFilterEnabled }, { suspense: true });
return (
<div>
<input
type="checkbox"
value={isFilterEnabled}
onChange={onFilterCheckboxChange}
/>
<MyBooks books={data} />
</div>
);
};
const Page = () => (
<Suspense fallback={<MyComponentSkeleton />}>
<MyComponent />
</Suspense>
);그런데 여기에서 startTransition을 쓸 경우, 데이터를 불러오는 동안 스켈레톤을 보여주지 않고 기존 데이터를 가지고 계속 보여주게 됩니다. 그리고 데이터를 다 불러오고 나면 새로운 데이터로 업데이트됩니다. 그렇기에 실제로는 체크 버튼을 누르면 한참 동안 반응이 없다가 업데이트가 일어납니다.
사실 사용하지 않은 isPending 이라는 값은 이 문제를 위한 값입니다. 이 값을 사용하면 하단의 input 옆에 isPending && <Spinner /> 를 추가해서 데이터를 가져오는 중임을 보여줄 수 있습니다.
그러나 저희는 이미 사용하는 스켈레톤이 있기에 바로 로딩 되는 것처럼 눈속임하고자, 간단히 startTransition을 제거하여 스켈레톤을 보여주게 하였습니다.
[1]: Suspense로 데이터를 불러오는 것은 React 18에서 새로 나온 데이터 불러오기 방식인데, 대략 다음과 같이 동작합니다.
1. 컴포넌트 내에서 데이터를 불러오는 Promise를 throw합니다.
2. 데이터를 불러올 동안 스켈레톤과 같은 폴백을 보여줍니다.
3. 데이터를 다 받으면 다시 컴포넌트 코드를 실행하여 결과물을 렌더링 합니다.
잘못된 필터링 로직을 수정하기
스켈레톤을 보여준다 한들 로딩이 오래 걸리는 문제는 고쳐야 합니다.
그리고 로딩이 오래 걸리는 원인은 필터를 바꿀 때마다 모든 작품을 다시 서버에서 불러오는 것이었습니다. 저희는 그 문제를 없애기 위해 필터링 정보를 받아서 프론트엔드에서 필터링 작업까지 수행하게 하였습니다.
type Ownership = { id: string, purchasable: boolean };
const ownerships: Ownership[] = [];
const purchasableFilter = ownerships.reduce<Record<string, boolean>>(
(partial, ownership) => ({ ...partial, [ownership.id]: ownership.purchasable }),
{},
);작품은 무조건 1번만 불러오게 되었으니 당연히 네트워크 코스트는 줄어들었습니다. 그런데 이렇게 하니 이상하게 페이지가 전체적으로 느려지기 시작했습니다.
느려지는 패턴이 메인스레드에 부하가 커졌을 때와 비슷하게 느껴져 프로파일링을 돌려보았습니다. 그리고 그 결과로 { id, shouldDisplayItem } 형태의 값을 { [id]: shouldDisplayItem } 형태로 바꾸는 데에 많은 시간을 쓰고 있는 것을 확인할 수 있었습니다.

위의 프로파일링 결과를 보면 필터링을 수행하는 데 1번에 4초씩, 무려 10초 넘게 CPU 타임을 쓰는 것이 보입니다. 그 이유를 찾기 위해 코드를 살펴봅시다. 위 코드에서는 순회하면서 스프레드로 계속 새로운 속성을 추가하고 있는데, 이 부분이 의심스럽습니다.
저희는 일단 저 부분의 구현을 Map을 사용하는 방식으로 바꿔서 해결했습니다. 바뀐 해결법에 대해서는 조금 있다가 이야기하고, 먼저 저 부분이 왜 문제가 되는지를 살펴봅시다.
잘못된 필터링 로직이 느린 이유
가장 첫 번째로 저런 코드가 짜여진 원인은 mutation을 피하기 위해서입니다. 저희는 AirBnB의 스타일 가이드를 기반으로 자체 스타일 가이드를 만들어서 작업하는데, 여기에 함수의 파라미터를 mutate 하지 말라는 eslint 규칙이 들어있습니다. 그렇기에 partial 값을 수정하지 않고, 스프레드로 새 값을 만들어서 mutation을 일으키지 않는 방향으로 코드를 작성하였습니다.
V8의 최적화는 일반적으로 저희의 생각보다 매우 똑똑하게 작동합니다. 그래서 스프레드로 값을 계속 추가하더라도 크게 느리지 않을 것이라는 생각을 하였습니다. 실제로도 ID가 10자리의 임의의 숫자라서 그렇지, ID를 0, 1, 2, … 와 같이 바꿔놓고 테스트해 보면 위 코드는 10ms 만에 돌아갑니다. 사실 위 코드를 따로 테스트해 봤을 때에는 0, 1, 2, …로 테스트했기에 정말 문제인지 확신하기까지 시간이 조금 걸렸습니다.
그렇다면 왜 0, 1, 2, … 일 때에는 10ms 만에 돌아가면서 10자리의 숫자일 때에는 4초씩이나 걸릴까요?
V8에는 내부적으로 느린 모드의 오브젝트와 빠른 모드의 오브젝트가 있습니다. 그 둘을 JS에서 일반적인 방법으로 구분하기는 어렵고, 대신 V8 내부 함수 중에 %DebugPrint 를 통해서 확인할 수 있습니다. Node.js에서 코드를 실행할 때 --allow-natives-syntax 플래그를 주어 V8 내부 함수를 실행시킬 수 있는데, 이걸로 purchasableFilter 객체를 찍어보았습니다.
확인해 보니 ID가 0, 1, 2, … 일 때에는 HOLEY_ELEMENTS 타입으로, ID가 10자리의 임의의 숫자일 때에는 DICTIONARY_ELEMENTS 타입으로 나왔습니다.
// ID = 0, 1, 2, ...
DebugPrint: (...): [JS_OBJECT_TYPE]
- map: (...) <Map(HOLEY_ELEMENTS)> [FastProperties]
- prototype: (...) <Object map = (...)>
- elements: (...) <FixedArray[6667]> [HOLEY_ELEMENTS]
- properties: (...) <FixedArray[0]>// ID = 476600001, 4291002444, …
DebugPrint: (...): [JS_OBJECT_TYPE]
- map: (...) <Map(DICTIONARY_ELEMENTS)> [FastProperties]
- prototype: (...) <Object map = (...)>
- elements: (...) <NumberDictionary[49156]> [DICTIONARY_ELEMENTS]
- properties: (...) <FixedArray[0]>두 오브젝트가 서로 타입이 다른 것은 구멍의 개수의 차이에서 기인합니다.
- 0…5999 는 사이사이에 빈 숫자가 없습니다. 이 케이스에서는 오브젝트를 길이가 6,000인 배열처럼 다루어도 큰 문제가 없어 보입니다. 따라서 이 케이스에서는 내부적으로 딕셔너리 대신 최적화된 형태로 취급합니다.
- 476600001, 4291002444, … (총 6,000개)에는 사이사이에 빈 “구멍”이 많습니다. 이 오브젝트를 처리하기 위해 길이가 억 단위인 배열을 만드는 것은 메모리 측면에서 당연히 비효율적입니다. 따라서 이 케이스에서는 내부적으로 딕셔너리처럼 처리합니다.
마찬가지로 V8은 스프레드 연산자도 두 케이스를 나누어서 처리합니다. 그렇기 때문에 ID가 0, 1, 2, … 일 때에는 더 최적화된 방식으로 처리되었고, ID가 임의의 10자리 숫자일 때에는 더 느린 방식으로 처리되어 속도 차이가 심하게 났던 것이었습니다.[2] 하지만 결국엔 두 케이스 전부 O(n^2) 으로 동작하였기 때문에, 어찌 됐든 이 방법은 사용할 수 없었습니다.
다시 문제로 돌아와서, 아까 전 언급했던 코드는 스프레드를 사용하지 않는 방법으로 수정할 수 있었습니다.
const purchasableFilterGood = new Map<string, boolean>();
ownerships.forEach(
({ id, purchasable }) => purchasableFilterGood.set(id, purchasable)
);간단히 Map 객체를 하나 만들고 루프를 돌며 집어넣게끔 변경하면, 1번에 4초나 걸리던 필터링 동작이 0.5ms로 8000배 가까이 줄어듭니다. 이렇게 필터링의 성능 이슈를 수정할 수 있었습니다.
이 문제를 통해서 알게 됐던 점은, 린트 룰을 무작정 따르기보다는 어떻게 수행될지를 한 번은 생각해 보고 코드를 짜야 한다는 점이었습니다.
[2]: 더 자세히 들어가 보고 싶으신 분들을 위해 조금 더 자세히 설명드리자면, 스프레드 연산자는 내부적으로 CloneObject 바이트코드로 번역됩니다.
그리고 그 CloneObject 는 오브젝트의 형태에 따라서 Monomorphic/Polymorphic, Slow, Miss의 케이스로 나뉘어 처리됩니다. 이 중에서 Slow 케이스와 Miss 케이스는 각각 CopyDataProperties 라는 런타임과 CloneObjectIC_Miss 라는 런타임을 호출하게 됩니다.
따라서 lldb와 같은 디버거로 V8을 디버깅하며 런타임 호출 횟수를 체크해 본다면, ID = 0, 1, 2, … 일 때에는 Monomorphic/Polymorphic 케이스를, ID가 10자리의 임의의 수일 때에는 Slow 케이스를 타고 있는 것을 확인할 수 있습니다.
4. 마크다운 이벤트를 마치며
이런 우여곡절 끝에 사용자분들께 올해의 마크다운 이벤트를 잘 전달할 수 있었습니다. 당연히 아직 더 개선할 여지는 많으니, 여기에서 그치지 않고 더 나아가 보고자 합니다.
- 페이지네이션 / 무한스크롤을 추가하고자 합니다 현재 구조에서는 랜딩 시간이 작품 갯수에 대해 선형적으로 느려지고 있습니다. 여기에 페이지네이션이나 무한 스크롤을 추가해서 지금 당장 그리지 않을 작품이 없더라도 먼저 보여줄 수 있다면 좋을 것 같습니다.
- 그 외 추가적인 기능 개선을 진행하고자 합니다 예시로, 현재 이벤트 페이지는 가상화를 넣으면서 브라우저의 페이지 내 검색 기능이 제대로 동작하지 않게 되었습니다. 물론 자체적인 검색 기능은 제공하고 있지만, 페이지 내에서 간단히 검색할 수 있는 기능을 추가하거나, 경량화된 제목 정도만이라도 렌더링 해서 기능이 작동하게 바꿀 수 있을 것 같습니다.
- 페이지 전체를 Next.js 로 이전하고자 합니다 전체를 리팩토링하기에는 일정 상 여유가 없어 기존의 레거시 PHP에서 페이지의 일부분만 리액트로 리팩토링하고 캐시를 직접 붙이는 식으로 작업했습니다. 따라서 이벤트 페이지의 전체 리팩토링을 마치고 기존의 Next.js 프로젝트에 추가해 관리 포인트를 줄이고 싶습니다.
사용자에게 더 쾌적한 경험을 제공하고자 하는 저희의 여정에 함께하시고 싶으시다면, 하단의 링크를 통해서 지금 바로 리디에 지원해 주세요. 읽어주셔서 감사합니다!
고객과 발맞춰 새로운 콘텐츠 경험을 선보이는
리디와 함께할 당신을 기다립니다.