Apache Spark는 대용량 데이터의 범용 계산을 위한 분산처리 시스템입니다. 기존의 Hadoop Map-Reduce에 비해 훨씬 빠르면서도 간편하게 복잡한 데이터 연산을 처리할 수 있습니다. 전 세계적으로도 많은 사용자층을 가지고 있으며, 2018년 8월 현재 2.3.1 버전까지 릴리즈되었을 정도로 유지보수도 꾸준히 이루어지고 있습니다. 이런 특성 때문에 리디 데이터팀에서도 베스트셀러, 개인화 추천, 각종 지표 집계 및 데이터 분석에 Spark 를 사용하고 있습니다.
Spark를 사용하다 보면 데이터를 일정한 조건으로 그룹화하는 연산을 자주 사용하게 됩니다. 매출 내역을 날짜별로 묶어서 합계를 낸다거나 하는 경우죠. 이를 위해서는 Spark SQL 에서 GROUP BY 절을 이용하는 것이 가장 간편하지만, 가끔 복잡한 연산을 필요로 할 때는 RDD API를 사용하는 것이 더 나을 때가 있습니다. RDD API를 사용하면 스칼라로 코드를 작성할 수 있기 때문에 복잡한 연산을 표현하기에 적절합니다.
Spark의 RDD에 그룹화 연산을 적용하려면, PairRDDFunctions 클래스에 있는 combineByKey 계열 메소드1를 사용하면 됩니다. 그 중에서도 가장 많이 쓰이는 두 개의 메소드가 groupByKey와 reduceByKey입니다.
오늘은 이 두 개의 메소드를 간략히 소개하고, 어느 상황에서 어떤 메소드를 쓰는 것이 적절한지 알아보겠습니다. 그리고 추가적으로, 저희가 실험을 통해서 groupByKey가 효율적이지 않게 구현되었다는 것을 알아낸 경험에 대해 이야기해보고자 합니다.
reduceByKey 와 groupByKey
reduceByKey는 combine 계열 API 중에서 가장 대표적인 메소드입니다. Spark 의 Word Count 예제에서도 사용하고 있지요. reduceByKey는 키-값 순서쌍 (key-value pair) 의 RDD 를 키(key) 가 같은 것들끼리 그룹으로 묶어서, 각 키마다 값(value) 의 그룹을 만든 후, 그 그룹에 주어진 reduce 연산을 적용하여 하나의 값으로 만드는 데에 사용합니다. 여기에 사용할 수 있는 reduce 연산은 대표적으로 합(sum), 최대(max), 최소(min) 연산 등이 있습니다.
reduceByKey를 쓰려면 어떤 V의 집합에 대해 reduce 연산을 계속해서 하나의 V 값으로 만들 수 있어야 합니다. 그리고 집합 내의 원소들에게 어떤 순서로 연산을 적용하든 간에 상관없이 같은 결과가 나와야 합니다. 이 조건을 좀더 수학적인 언어로 표현하면 다음과 같습니다.
- 두 입력값과 출력값의 타입이 같다.
f: (V, V) => V - 연산에 교환법칙이 성립해야 한다.
f(v1, v2) == f(v2, v1) - 연산에 결합법칙이 성립해야 한다.
f(v1, (v2, v3)) == f((v1, v2), v3)
그룹에 대해서 위 조건을 만족하지 않는 연산을 적용하려면 reduceByKey로는 어렵고, groupByKey를 사용해야 합니다.
groupByKey는 키-값 순서쌍의 RDD 를 키(key)가 같은 것들끼리 묶어서, 키-그룹 순서쌍의 RDD를 만들어 줍니다. 스칼라의 타입으로 표현하면 RDD[(K, V)]를 입력으로 받아서 RDD[(K, Iterable[V])]을 만들어 주는 겁니다. 그리고 나서 Iterable[V]에 대해 자유롭게 루프를 돌면서 원하는 일을 할 수 있기 때문에, reduceByKey보다는 좀더 자유롭게 사용할 수 있습니다.
그런데 공식 API 문서를 비롯한 여러 곳에서는 groupByKey의 사용을 권장하지 않고 있습니다.
Note: This operation may be very expensive. If you are grouping in order to perform an aggregation (such as a sum or average) over each key, using PairRDDFunctions.aggregateByKey or PairRDDFunctions.reduceByKey will provide much better performance.
즉, 어차피 Iterable[V]에다가 대고 무언가 집계(aggregation) 연산을 할거면, 처음부터 groupByKey를 쓰지 말고 reduceByKey나 aggregateByKey를 쓰라는 것이지요. 이렇게 해야 하는 이유는, groupByKey는 내부적으로 map-side combine을 하지 않도록 되어 있기 때문입니다.
map-side combine이란, 셔플 이전 단계에서 파티션 내에서 같은 키를 가지는 값들끼리 미리 combine 연산을 한 후에 다음 단계로 내보내는 것을 말합니다. 이렇게 하면 네트워크를 타고 넘어가는 데이터의 크기도 적고, 셔플 이후 단계에서 메모리에 올려야 하는 레코드의 수도 줄어들기 때문에 훨씬 효율적입니다. map-side combine이 효율적인 이유에 대해서는 이 문서에서 자세히 설명하고 있습니다.
groupByKey 대신에 reduceByKey 사용하기: 1단계
그러면 groupByKey를 어느 정도까지 피할 수 있을까요? 교환법칙과 결합법칙이 성립하는 연산이 아니라면 groupByKey를 써야만 하는 걸까요?
꼭 그런 건 아닙니다. 얼핏 생각했을 때 groupByKey를 써야 할 것 같은 경우도, 조금만 트릭을 사용하면 reduceByKey를 써서 해결할 수 있는 경우가 많습니다.
예제1: 날짜별로 매출 평균 구하기
// RDD of (date, book_id, revenue)
val revenueByBook: RDD[(LocalDate, String, Long)]
// using groupByKey
val revenueByDay1: RDD[(LocalDate, Double)] = revenueByBook
.map({case (date, bookId, revenue) => (date, revenue)})
.groupByKey()
.mapValues({case (scores: Iterable[Long]) =>
val scoresArray = scores.toArray
val sum = scoresArray.sum
val count = scoresArray.length
sum.toDouble / count
})
// using reduceByKey
val revenueByDay2: RDD[(LocalDate, Double)] = revenueByBook
.map({case (date, bookId, revenue) => (date, (revenue, 1))})
.reduceByKey({
case ((sum1, count1), (sum2, count2)) => (sum1+sum2, count1+count2)
})
.mapValues({case (sum, count) =>
sum.toDouble / count
})
단순한 수끼리의 덧셈 뿐만 아니라, 여러 개의 수를 원소로 갖는 튜플끼리의 덧셈 또한 교환법칙과 결합법칙이 성립한다는 점을 이용했습니다. 1번의 groupByKey가 1번의 reduceByKey로 대체되었기 때문에, 명백히 reduceByKey를 사용하는 편이 더 효율적입니다.
그러나 reduceByKey로 대체하는 것이 꼭 효율적이지만은 않은 경우도 있습니다.
예제2: 날짜별로 구매자수 세기
// RDD of (userId, date, bookId)
val purchases: RDD[(Int, LocalDate, String)]
// using groupByKey
val numPurchaseDatesByUser1: RDD[(LocalDate, Int)] = userPurchaseRDD
.map({case (userId, date, bookId) => (date, userId)})
.groupByKey()
.mapValues(userIds: Iterable[Int] => userIds.toSet.size) // all userIds within a date are loaded to memory
// using reduceByKey
val numPurchaseDatesByUser2: RDD[(LocalDate, Int)] = userPurchaseRDD
.map({case (userId, date, bookId) => (date, userId)})
.distinct()
.mapValues(_ => 1)
.reduceByKey(_ + _)
groupByKey를 사용하지 않도록 대체하려면 distinct와 reduceByKey를 각각 한 번씩 호출해야 하기 때문에, 총 2번의 셔플이 들어갑니다. 셔플 과정은 전체 데이터가 한번씩 네트워크를 타고 전달되어야 하기 때문에 비용이 큽니다. 따라서 웬만한 경우에는 groupByKey를 사용하는 것이 낫다고 여길 수 있습니다.
그러나 생각해 봐야 할 것이 있습니다. userIds: Iterable[Int] => userIds.toSet.size 이 부분을 실행하는 시점에, 해당 날짜의 모든 트랜잭션의 건수와 동일한 수의 userId가 메모리에 올라갑니다. 이 숫자는 수백만에서 수천만까지 쉽게 올라갈 가능성이 있습니다. JVM 프로세스가 이 정도 크기의 콜렉션을 메모리에 올리는 것은 큰 부담이 됩니다. 스파크 익스큐터(Spark executor)는 이 코드를 처리하면서 가비지 콜렉션만 하다가 많은 시간을 허비할 확률이 높습니다. 결국에는 OutOfMemoryError를 내며 비정상 종료되거나, 정상적으로 종료되더라도 이미 많은 시간을 낭비한 후일 것입니다.
따라서 groupByKey의 결과로 나오는 그룹의 최대 크기가 아주 큰 경우에는, 가능하면 groupByKey를 피하고 여러 번의 셔플을 하게 되더라도 reduceByKey로 대체하는 것이 낫습니다.
groupByKey의 사용이 아예 불가피한 경우도 있습니다. 그룹 내의 원소를 반드시 전부 메모리에 올려놓고 무언가 계산을 해야 하는 경우가 그렇습니다. 리디 데이터팀에서는 도서간 Jaccard 유사도를 구하기 위해, 각 도서의 구매자 집합을 groupByKey로 전부 메모리에 올려 놓고 두 집합간의 교집합과 합집합을 계산해야 했습니다. 이렇게 그룹을 가지고 복잡한 계산을 하거나, 그룹에 대해서 여러 번 순회하며 무언가 계산해야 하는 경우에는 groupByKey를 사용할 수밖에 없는 것 같습니다.
정리하자면 다음과 같습니다.
- 다음과 같은 경우에는
groupByKey를 쓰는 것이 좋습니다.- 그룹 전체를 메모리에 올려서 복잡한 계산을 수행하거나 여러 번 순회하며 계산해야 하는 경우
- 그룹의 최대 크기가 부담없이 메모리에 올라갈 정도로 작으면서,
reduceByKey로 대체했을 때의 셔플 횟수가groupByKey를 썼을 때보다 큰 경우
- 다음과 같은 경우에는
reduceByKey로 대체하는 것이 좋습니다.- 그룹의 최대 크기가 메모리에 올리기 부담스러울 정도로 클 경우
reduceByKey로 대체했을 때의 셔플 횟수가groupByKey를 썼을 때보다 작거나 같은 경우
groupByKey 대신에 reduceByKey 사용하기: 2단계
위에서 보았듯이 어쩔 수 없이 groupByKey를 사용해서 그룹을 전부 메모리에 올려야 하는 경우도 있습니다. 하지만 map-side combine을 사용하지 않는 등, groupByKey가 갖는 비효율성 때문에 역시 사용하기가 꺼려집니다. 다른 방법은 없는걸까요?
연결(concatenation) 연산은 두 개의 콜렉션을 이어서 하나로 만드는 연산입니다. 두 개 이상의 콜렉션을 연결해서 하나로 만들 때, 콜렉션 내에서 원소의 순서가 중요하지 않다면, 연결 연산을 어떤 순서로 적용하든간에 결과 콜렉션은 실질적으로 동일합니다. 따라서, 연결 연산은 교환법칙과 결합법칙을 만족한다고 할 수 있습니다. 이 점을 이용하면 다음과 같이 groupByKey와 결과가 완전히 동일한 연산을 reduceByKey를 가지고 만들어낼 수 있습니다.
(K, V)의 RDD 에서 각V로부터 길이 1짜리 배열을 생성해서,(K, Array[V])의 RDD 로 변환한다.(K, Array[V])의 RDD에Array끼리의 연결(++) 연산을 적용해reduceByKey를 실행한다.
코드로 작성해 보면 다음과 같습니다.
val keyValuePairRDD: RDD[(String, Int)]
val groupedRDD1: RDD[(String, Iterable[Int])] = keyValuePairRDD
.mapValues(n => Array(n))
.reduceByKey({case (arr1, arr2) => arr1 ++ arr2})
.asInstanceOf[RDD[(String, Iterable[Int])]]
val groupedRDD2: RDD[(String, Iterable[Int])] = keyValuePairRDD
.groupByKey()
이 코드를 실행해 보면 groupByKey와 완전히 똑같은 결과가 나옵니다. 그리고 map-side combine을 사용하므로 groupByKey보다 더 효율적일 것으로 예상됩니다. 그러면 앞으로 groupByKey 대신에 전부 이런 식의 코드를 사용하면 될까요?
그렇게 하기 전에 몇 가지 짚고 넘어가야 할 것이 있습니다.
groupByKey 소스코드 파헤치기
우선, Array의 연결 연산의 효율성에 대해 주목해 봅시다. Array 는 가변(mutable) 콜렉션이지만, 연결(++) 연산을 수행할 때는 마치 List와 같은 불변(immutable) 콜렉션들처럼 작동합니다. 즉, 길이 m 짜리 Array와 길이 n 짜리 Array를 연결한다고 하면, 원래의 두 객체는 그대로 두고 새로운 Array 객체를 만들어서 원소들을 각각 복사해 주는 식으로 작동합니다. 따라서 연결 연산의 시간복잡도는 O(1)이 아니라 O(m+n)입니다. 그렇기 때문에, 길이 1짜리 Array를 n개 연결해서 길이 n 짜리 Array를 만드는 작업의 시간복잡도는 O(n)이 아니라 O(n * log n )이 됩니다.2
이는 ++= 연산을 제공하지 않고 ++ 연산만 제공하는 모든 콜렉션에 대해서 마찬가지입니다. ++= 연산은 ++ 와는 달리, 기존 콜렉션에 다른 콜렉션의 원소들을 붙여서 업데이트하는 식으로 동작하므로 약간 더 효율적입니다. Array를 제외한 대부분의 가변 콜렉션은 ++= 연산을 제공합니다. 그러면 Array 대신에 ArrayBuffer처럼 ++= 연산을 제공하는 콜렉션을 사용하면 되지 않을까요?
하지만 그 전에 groupByKey 의 소스코드를 한번 들여다 봅시다. groupByKey의 메소드 구현을 정리해 보면 다음과 같습니다.
(K, V)의 RDD 에서 각V로부터 길이 1짜리CompactBuffer를 생성해서,(K, CompactBuffer[V])의 RDD 로 변환한다.(K, CompactBuffer[V])의 RDD에CompactBuffer끼리의 연결(++=) 연산, 또는CompactBuffer에 원소를 추가(+=) 하는 연산을 적용해combineByKeyWithClassTag를 실행한다. 단, map-side combine은 사용하지 않는다.
reduceByKey 대신에 combineByKeyWithClassTag를 사용하기는 하지만, 우리가 위에서 Array와 reduceByKey를 사용해 작성했던 코드와 거의 유사합니다. (reduceByKey도 사실 내부적으로 combineByKeyWithClassTag를 사용합니다.) 게다가 CompactBuffer 자체가 ArrayBuffer와 비슷하게 ++= 연산을 제공하는 가변 콜렉션입니다.
이번에는 CompactBuffer 의 소스코드를 들여다 봅시다. 주석에 언급된 바로는, CompactBuffer는 ArrayBuffer에 비해 오버헤드를 줄이도록 설계되었다고 합니다. 원소가 2개 이하일 때는 내부 배열을 아예 사용하지 않고, 직접 객체의 필드에 저장하는 방식입니다. 이를 고려했을 때 적어도 ArrayBuffer보다는 높은 성능을 낼 것으로 보입니다.
그러면 ArrayBuffer와 reduceByKey를 사용해 봤자 이미 groupByKey가 그보다 효율적으로 설계되었으므로 소용없는 일이 아닐까요? 꼭 그렇지만은 않을 것 같습니다. 두 가지 면에서 그렇습니다.
groupByKey는 map-side combine을 사용하지 않도록 설계되었습니다.groupByKey의 소스코드 주석에 따르면,groupByKey의 경우는 map-side combine을 해봤자 셔플로 넘어가는 데이터의 크기는 그대로이기 때문에, 오히려 더 비효율적이라는 이유로 map-side combine을 비활성화했습니다. 그러나 과연 정말로 이 때문에 map-side combine을 포기하는 것이 좋은지는 의문입니다.(K, V)를(K, CompactBuffer[V])로 만든다고 했을 때, 셔플을 통해 넘어가는V의 개수는 map-side combine 을 한다고 해도 그대로인 것이 맞습니다. 그러나K의 개수는 명백히 줄어듭니다. 간단히 말해서, 네트워크를 타고(Int, Long)이 100개 넘어가는 것과(Int, 100개짜리 CompactBuffer[Long])이 1개 넘어가는 것은, 아무리 생각해도 후자가 효율적입니다. 이로 인한 이득이 주석에서 이야기한 “해시테이블에 데이터를 집어넣는 비용” 과 비교했을 때 어떤 것이 더 큰지는 직접 실험해 봐야 알 수 있을 것입니다.CompactBuffer의++=연산 또한O(1)이 아닙니다. 길이m짜리CompactBuffer에 길이n짜리CompactBuffer를 연결할 때, 길이n짜리의 원소 전체가 길이m짜리CompactBuffer로 복사됩니다. 복사하는 과정은 당연히O(n)의 시간이 걸립니다. 이 과정이System.arraycopy호출을 통해 효율적으로 실행되기는 하지만, 길이가 아주 긴 콜렉션의 경우 그에 비례해서 시간이 늘어나는 것은 마찬가지입니다. 우리가 상식적으로 생각했을 때, 원본 콜렉션 두 개를 모두 유지할 필요가 없는 상황에서는, 콜렉션끼리 연결하는 연산은O(1)이면 충분합니다. 스칼라에서는UnrolledBuffer라는 가변 콜렉션이 이런 특성을 구현하고 있습니다. 이 클래스의concat메소드를 사용하면O(1)의 시간에 콜렉션끼리 연결할 수 있습니다.
정리해 보면, 다음과 같은 조건들에 대해 성능을 측정해 보면 될 것 같습니다.
- 길이 1짜리
ArrayBuffer에 대해++=연산으로reduceByKey실행 - 길이 1짜리
ListBuffer에 대해++=연산으로reduceByKey실행 - 길이 1짜리
UnrolledBuffer에 대해concat연산으로reduceByKey실행 - 길이 1짜리
CompactBuffer에 대해++=연산으로reduceByKey실행 - 단순히
groupByKey실행
ArrayBuffer와 ListBuffer는 둘 다 대표적인 가변 콜렉션이라는 점에서 실험대상에 추가했습니다. UnrolledBuffer는 O(1) 짜리 연결 연산이 효율적이라는 가설을 검증하기 위해서 추가했습니다. 나머지 CompactBuffer와 groupByKey의 비교를 통해서는 map-side combine의 영향을 알아볼 수 있을 것입니다.
실험 설계
실험에 사용한 코드: TestGrouping.scala
실험의 세부 내용은 다음과 같습니다.
(Int, Long)의 순서쌍이 1억개 들어 있는 RDD 를 만든다.- 값(value)에 해당하는
Long은 평균 0.0, 표준편차 1,000,000 인 정규분포를 가진다. - 키(key)에 해당하는
Int는Long값을 각각 100,000 으로 나눈 몫이다.
- 값(value)에 해당하는
- 위의 RDD 를
Int키를 기준으로 그룹핑하되, 위에서 언급한 5가지 방법을 사용한다. - 각 그룹별로 원소의 개수, 평균, 표준편차를 구하여 하이브 테이블에 저장한다.
- 각 방법의 실행시간을 비교한다.
부연 설명:
- 정규분포를 사용한 이유는, 각 키마다 그룹 크기에 차이를 두기 위함입니다. 이렇게 하면 어떤 방법이 작은 그룹에 효율적이고 어떤 방법이 큰 그룹에 효율적인지 알 수 있겠지요.
- 위에서 평균/표준편차는
groupByKey등을 써서 그룹을 메모리에 올리지 않고도 구할 수 있다고 하였지만, 그룹을 순회하면서 계산하기에 적절한 연산인 것 같아 예제로 사용하였습니다. CompactBuffer는private[spark]로 정의되어 있어,org.apache.spark패키지 외부에서는 사용할 수 없습니다. 그래서 위 코드는org.apache.spark.test.app패키지 내에 만들어서 실행했습니다.
정리하면 다음과 같이 되겠습니다.
| 애플리케이션 | 그룹핑에 사용된 API | 콜렉션 타입 | reduce 연산 |
|---|---|---|---|
TestReduceByKeyWithArrayBuffer | reduceByKey | ArrayBuffer | ++= |
TestReduceByKeyWithListBuffer | reduceByKey | ListBuffer | ++= |
TestReduceByKeyWithUnrolledBuffer | reduceByKey | UnrolledBuffer | concat |
TestReduceByKeyWithCompactBuffer | reduceByKey | CompactBuffer | ++= |
TestGroupByKey | groupByKey | N/A | N/A |
실험 결과
위의 5가지 스파크 애플리케이션을 다음과 같은 조건의 클러스터에서 실행해 보았습니다.
- AWS EMR 버전 5.16.0
- Spark 버전 2.3.1
- 슬레이브 노드: r3.xlarge (4 vCPU, 30.5 GiB RAM) X 5대
reduceByKey와 groupByKey를 사용했을 때 모두, 각 애플리케이션은 2개의 스테이지로 나누어서 실행됩니다.
- Stage 0
RDD[Long]생성map과keyBy로 RDD[(Int, Long)] 생성- (
reduceByKey를 쓰는 경우)mapValues로RDD[(Int, Collection[Long])]생성 - map-side combine 단계 포함
- 셔플
- Stage 1
- (
reduceByKey를 쓰는 경우) 셔플된 콜렉션끼리 연결 - (
groupBykey를 쓰는 경우) 셔플된Long끼리 연결하여 콜렉션 생성 - 콜렉션을 순회하면서
count,mean,std_dev를 계산 - 계산된 통계값을 하이브 테이블에 저장
- (
Spark Web UI를 보면 다음 화면과 같이 각 스테이지에 대한 상세한 태스크별 실행 내역이 나옵니다.
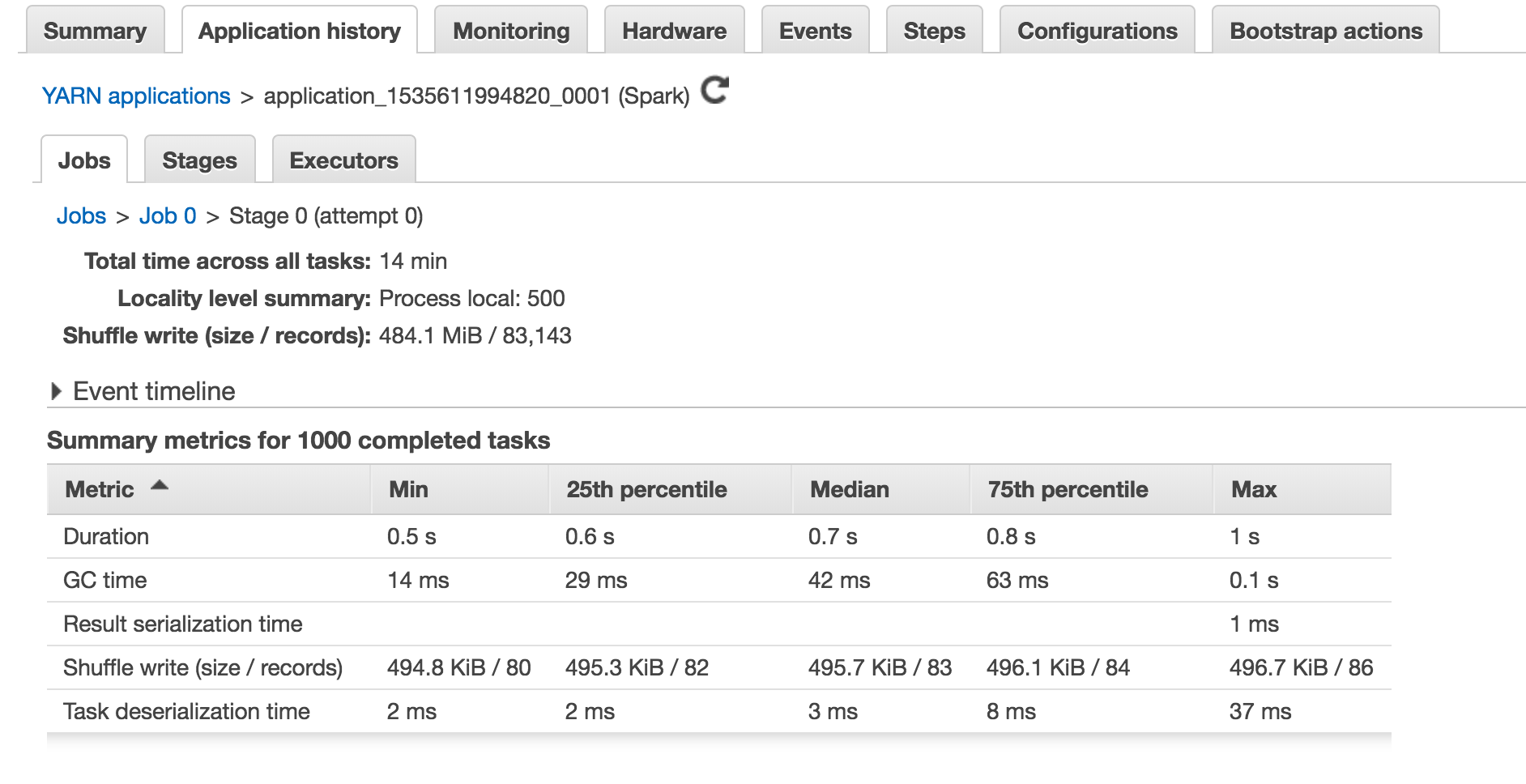
스테이지를 구성하는 각각의 태스크 가 어느 익스큐터에서 실행되었는지, 그리고 얼마나 시간이 걸렸는지도 알 수 있고, 태스크 전반에 대한 실행시간 통계도 나옵니다. 특히 0, 25, 50, 75, 100 백분위수마다의 실행시간을 보여주기 때문에, 오래 걸리는 태스크와 적게 걸리는 태스크들이 어떻게 분포되어 있는지 파악하기가 쉽습니다.
결과적으로 가장 중요한 지표는 태스크 실행시간 합계 (Total Time across All Tasks)와 태스크 실행시간 최댓값 (Duration: Max)일 것입니다. 태스크간 실행시간이 어느정도 균등하다면, 스테이지 전체가 완료되는 시간에는 합계가 가장 많은 영향을 미칠 것입니다. 그리고 다른 태스크에 비해 특히 오래 걸리는 태스크가 존재한다면, 최댓값이 많은 영향을 미치겠죠.
각 스테이지의 통계는 다음과 같았습니다.
Stage 0 태스크별 실행시간 통계
| 애플리케이션 | 합계 | 최솟값 | 25 백분위수 | 중앙값 | 75 백분위수 | 최댓값 |
|---|---|---|---|---|---|---|
| TestReduceByKeyWithArrayBuffer | 14 min | 0.5 s | 0.6 s | 0.7 s | 0.8 s | 1 s |
| TestReduceByKeyWithListBuffer | 37 min | 1s | 2s | 2s | 2s | 3s |
| TestReduceByKeyWithUnrolledBuffer | 14 min | 0.5 s | 0.6 s | 0.7 s | 0.8 s | 1 s |
| TestReduceByKeyWithCompactBuffer | 5.9 min | 0.2 s | 0.2 s | 0.3 s | 0.3 s | 0.8 s |
| TestGroupByKey | 15 min | 0.4 s | 0.5 s | 0.7 s | 1.0 s | 2 s |
Stage 1 태스크별 실행시간 통계
| 애플리케이션 | 합계 | 최솟값 | 25 백분위수 | 중앙값 | 75 백분위수 | 최댓값 |
|---|---|---|---|---|---|---|
| TestReduceByKeyWithArrayBuffer | 16 min | 49 ms | 89 ms | 0.8 s | 4 s | 22 s |
| TestReduceByKeyWithListBuffer | 56 min | 66 ms | 98 ms | 0.9 s | 23 s | 1.6 min |
| TestReduceByKeyWithUnrolledBuffer | 15 min | 57 ms | 96 ms | 0.9 s | 3 s | 20 s |
| TestReduceByKeyWithCompactBuffer | 12 min | 52 ms | 90 ms | 0.8 s | 3 s | 16 s |
| TestGroupByKey | 14 min | 81 ms | 0.1 s | 1.0 s | 3 s | 18 s |
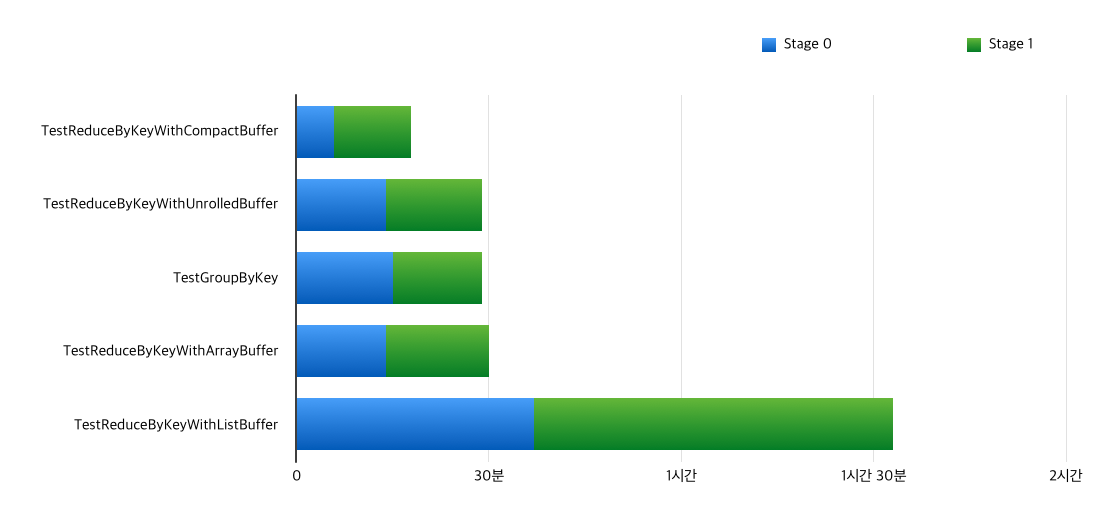
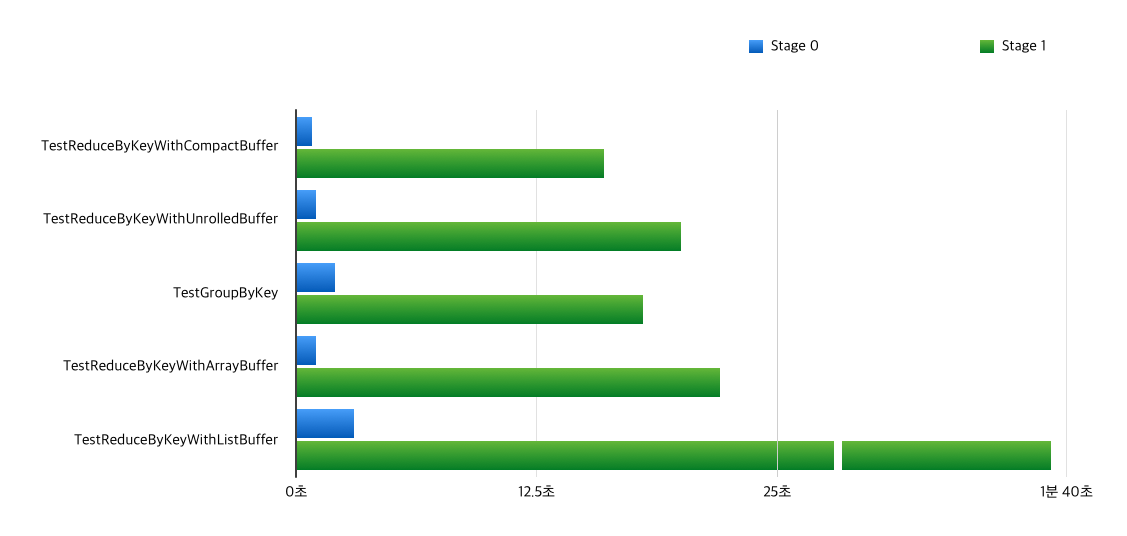
애플리케이션별로 쉽게 비교할 수 있도록 합계와 최댓값 수치만 차트로 그려 보았습니다.
태스크별 실행시간 합계 비교
태스크별 실행시간 최댓값 비교
실험 결과 분석
CompactBuffer를reduceByKey와 함께 사용한 경우가 두 스테이지 모두 가장 성능이 좋았습니다.특히 O(1)의 연결 연산을 사용한UnrolledBuffer보다도 성능이 좋은 것이 인상적입니다. 길이 1, 2 짜리 짧은 콜렉션이 많이 사용되는 Stage 0 에서 성능이 압도적인 것으로 보아,CompactBuffer가 짧은 콜렉션에서 효율적이라는 것이 사실임이 드러났습니다.groupByKey를 사용한 경우는UnrolledBuffer를reduceByKey와 사용했을 때와 대략 비슷한 성능을 보였습니다. 그러나 같은 콜렉션에 map-side combine 여부만 다른 경우인CompactBuffer+reduceByKey보다는 떨어지는 성능을 보였습니다. 위에서 이야기했듯이groupByKey구현에서 map-side combine을 비활성화한 것은 좋은 선택이 아닌 것 같습니다.UnrolledBuffer는ArrayBuffer보다 성능이 좋긴 했지만, 의외로 차이가 크지 않습니다. 아마도 배열을 복사하는 데에 드는 오버헤드가 그렇게 크지 않아서,O(1)짜리 연결 연산이 그렇게 큰 역할을 하지 않은 것 같습니다. 정규분포가 아닌 균등분포를 사용하고, 그룹의 크기를 좀더 늘리면 차이가 벌어질 수도 있겠습니다. (위 실험에서 가장 큰 그룹의 크기는 약 8백만 정도입니다.)ListBuffer는 모든 경우에 최악의 성능을 보였습니다. 객체 생성과 연결 연산 모두 오버헤드가 큰 것으로 보입니다.
RDD[(K, V)]를 RDD[(K, Iterable[V])]로 만드는 데에 groupByKey가 가장 효율적인 방법이 아니라는 사실을 알게 되었습니다. 실험 전에는 groupByKey의 소스코드에 적힌 주석이 어느정도 근거가 있을 거라고 믿었기 때문에 이 결과에 상당히 놀랐습니다. 사실 해당 주석을 포함한 코드가 Spark 소스코드에 제출된 것은 약 5년 전인 2013년 6월이고, 이 시점의 셔플과 map-side combine 관련 구현은 지금과 큰 차이가 있습니다. 예를 들어, 당시에는 진짜로 java.util.HashMap 에 객체를 넣는 코드가 존재했습니다. 하지만 지금은 해당 부분이 ExternalAppendOnlyMap이라는 Map 에 넣는 것으로 바뀌었습니다. 이것이 map-side combine의 성능에 직접적인 영향을 미쳤는지, 아니면 다른 이유가 있는지는 확실하지 않습니다. 그러나 지금 시점에서는 map-side combine을 쓰는 것이 쓰지 않는 것보다 더 효율적인 경우도 있다는 것은 확실합니다.
맺음말
이번 포스팅을 준비하고 실험을 진행하면서 많은 것을 배울 수 있었습니다.
먼저, API 를 사용하더라도 내부 구조를 알고 사용하는 것과 모르고 사용하는 것은 다르다는 것입니다. 사실 저희 팀에서도 처음에는 일부 코드에 Array 의 ++ 연산을 reduceByKey와 함께 사용하면서, 막연히 이게 더 효율적이지 않을까? 라고 생각하고 있었습니다. 그러나 이 포스팅에는 자세히 적지 않았지만, groupByKey와 Array + reduceByKey의 성능을 직접 실험을 통해 비교해본 후에야 ++ 연산의 문제를 알게 되었습니다. 우리가 흔히 쓰는 Array 같은 콜렉션도 비효율적으로 구현된 메소드가 있을 수 있으니 신중하게 사용해야 한다는 교훈을 얻었습니다.
두 번째로, 소스코드에 답이 있다는 것입니다. 처음에 groupByKey가 Array + reduceByKey보다 효율적이라는 것을 알게 되었을 때, 처음에는 영문을 몰라 어리둥절했습니다. 그러나 groupByKey 의 소스코드를 찾아본 후에는 ++ 연산과 ++= 연산의 차이 때문이라는 것을 알게 되었습니다. 그리고 소스코드를 더 들여다본 후에 map-side combine에 대해서도 좀더 자세히 알게 되었고, 이어서 ArrayBuffer를 reduceByKey와 함께 사용하면 더 효율적일 수도 있다는 가설도 세울 수 있게 되었습니다. 앞으로 Spark를 사용하면서 다른 문제에 부딪치더라도 소스코드를 파악함으로써 좀더 쉽게 문제를 해결할 수 있지 않을까 합니다.
이번 실험으로 얻은 결과는 Spark 개발 커뮤니티에 리포트하고, 가능하면 PR로 이어져서 프로젝트에 기여할 수 있도록 해 볼 예정입니다. 기여가 잘 진행된다면 다시 포스팅을 통해 공유해 드리도록 하겠습니다.
감사합니다.
combineByKey,aggregateByKey,foldByKey,groupByKey,reduceByKey의 다섯 가지 메소드는 시그니처가 조금씩 다르지만 모두 비슷한 역할을 수행하며, 내부적으로combineByKey를 호출하도록 구현되어 있습니다. 그래서 이들을 통틀어서combineByKey계열 메소드라고 표현하였습니다. ↩- 길이 1짜리
n개 연결 + 길이 2짜리n/2개 연결 + 길이 4짜리n/4개 연결 + … + 길이n/2짜리 2개 연결 =O(1) * n + O(2) * n/2 + O(4) * n/4 + ... + O(n/2) * 2=O(n * log n)↩
리디 기술 블로그
고객과 발맞춰 새로운 콘텐츠 경험을 선보이는
리디와 함께할 당신을 기다립니다.